

En février 2026, la startup Oumi a soumis les AI Overviews de Google — les résumés générés par intelligence artificielle qui apparaissent en tête des pages de résultats depuis 2024 — à un protocole de test rigoureux, commandité par le New York Times. Le verdict de surface est flatteur : avec Gemini 3, le modèle sous-jacent aux AIO depuis début 2026, le taux de précision factuelle atteint 91%, contre 85% avec Gemini 2 testé en octobre 2025. Une progression mesurable, que Google a mise en avant dans ses communications.
Mais derrière cette amélioration se dissimule un renversement bien plus préoccupant, passé presque inaperçu dans la couverture médiatique grand public : à mesure que les réponses deviennent plus souvent exactes, elles deviennent structurellement moins vérifiables. Ce n’est pas une nuance : c’est une contradiction au coeur du modèle de confiance sur lequel repose toute l’architecture de la recherche augmentée par l’IA.
L’article du NYT qui a tout déclenché
Le paradoxe du grounding
Le concept de grounding (ou ancrage) désigne, dans le contexte des systèmes RAG — Retrieval-Augmented Generation, c’est-à-dire des modèles d’IA qui consultent des sources externes avant de formuler une réponse — la capacité à lier chaque affirmation à une source qui la soutient effectivement et vérifiablement.
Un résultat est dit « non ancré » (ungrounded) lorsque la citation fournie ne corrobore pas réellement le contenu de la réponse : la source existe, elle est mentionnée, mais elle ne dit pas ce que l’IA prétend qu’elle dit.
Les données Oumi révèlent une évolution inverse entre accuracy et grounding :
- Avec Gemini 2 (octobre 2025) : 85% de précision, 37% de réponses correctes mais non ancrées
- Avec Gemini 3 (février 2026) : 91% de précision, 56% de réponses correctes mais non ancrées
En six mois, la précision a progressé de 6 points. Dans le même temps, la part des réponses exactes impossibles à vérifier via les sources citées a bondi de 19 points. Autrement dit : Google fournit davantage de bonnes réponses, mais de moins en moins de moyens de confirmer qu’elles le sont.
Quand la bonne réponse devient invérifiable
Le CEO d’Oumi, Manos Koukoumidis, a formulé le problème avec une précision qui mérite d’être citée : « Même quand la réponse est vraie, comment peut-on le savoir ? Comment peut-on vérifier ? »
La question n’est pas rhétorique. Elle pointe un défaut structurel des systèmes LLM (Large Language Models), modèles de langage de grande taille entraînés sur des corpus massifs — lorsqu’ils opèrent en mode génératif : leur tendance à produire des hallucinations, c’est-à-dire des affirmations présentées avec assurance mais non fondées sur les données disponibles, est de mieux en mieux masquée par une précision factuelle croissante.
Plusieurs exemples documentés par l’analyse illustrent la nature du problème mieux que n’importe quel agrégat statistique :
- Interrogé sur la date à laquelle la maison de Bob Marley a été convertie en musée, le système a répondu 1987. La date réelle est le 11 mai 1986. Les trois sources citées en appui ne fournissaient pas l’information correcte, ou la contredisaient.

- Questionné sur l’appartenance du violoncelliste Yo-Yo Ma au Classical Music Hall of Fame, l’AIO a affirmé qu’il n’existait aucun enregistrement de son adhésion — tout en pointant vers le site officiel de l’organisation, qui liste Ma parmi ses 165 membres depuis 2007.
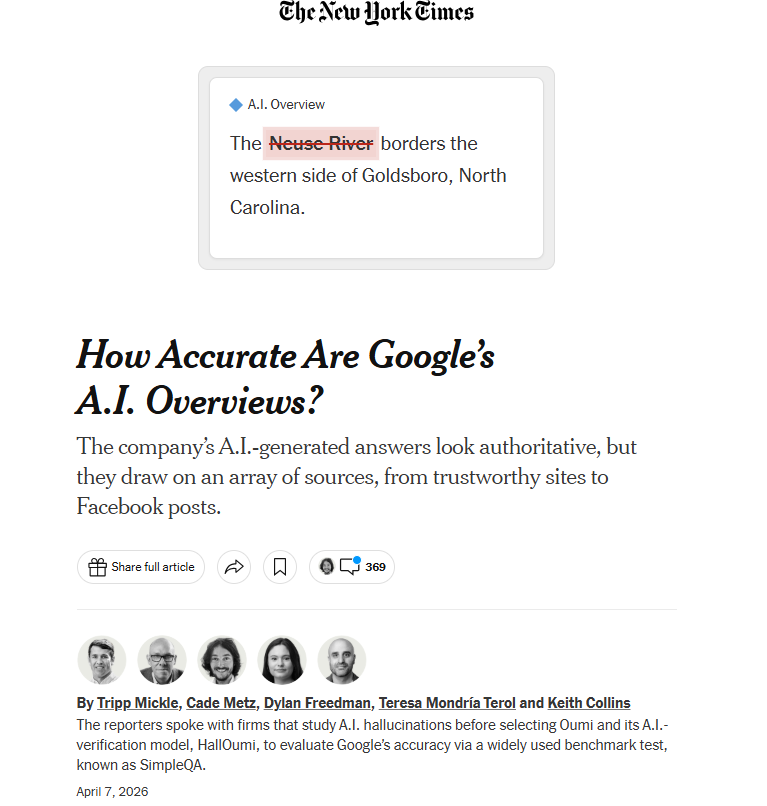
- Interrogé sur la rivière bordant l’ouest de Goldsboro, en Caroline du Nord, le système a désigné la Neuse River. La réponse correcte est la Little River.
Dans chacun de ces cas, le problème n’est pas une absence de sources : les liens sont là. C’est la cohérence entre la source et l’affirmation qui fait défaut.
Le rôle des sources : Facebook, Reddit et la hiérarchie inversée
L’analyse Oumi a également examiné la provenance des 5 380 citations utilisées par les AI Overviews. Les résultats interrogent directement la logique de sélection des sources :
- Facebook est le deuxième domaine le plus cité toutes catégories confondues
- Reddit occupe la quatrième position
- Pour les réponses inexactes, Facebook est cité dans 7% des cas, contre 5% pour les réponses correctes
Ce différentiel est modeste, mais révélateur d’une tendance : les réseaux sociaux, dont les contenus ne sont ni modérés éditorialement ni structurés pour la vérifiabilité, constituent une proportion significative de la base documentaire des AIO. Or, un système RAG se comporte comme la somme de ses sources : si les documents d’entrée sont ambigus, contradictoires ou non datés — ce qui est fréquent sur Facebook et Reddit — la réponse générée peut être statistiquement plausible sans être factuellement ancrée.
Google n’a pas communiqué publiquement sur la composition précise de sa base de sources ni sur ses critères de pondération. Cette opacité est elle-même un obstacle à la vérification externe.
Ce que dit la réponse de Google (et ce qu’elle ne dit pas)
Face à la publication de l’étude, Google a contesté la validité du benchmark SimpleQA utilisé par Oumi. Un benchmark est un protocole standardisé permettant de comparer les performances de systèmes différents sur un ensemble de tâches identiques. SimpleQA, développé par OpenAI, a en effet été conçu initialement pour des scénarios sans accès internet — ce qui ne reflète pas le fonctionnement des AIO, qui opèrent en mode RAG. De plus, SimpleQA est calibré sur des questions difficiles, pré-filtrées pour faire échouer au moins un modèle lors de la phase de conception : le taux d’échec y est structurellement plus élevé que sur un corpus de requêtes quotidiennes.
L’étude d’Oumi a créé un bad buzz, amplifié par beaucoup d’articles de presse. Google a dû réagir et répondre aux critiques
Le porte-parole de Google, Ned Adriance, a déclaré que l’étude « présente des lacunes sérieuses » et « ne reflète pas les requêtes réelles des utilisateurs Google ». Ces objections sont recevables sur le plan méthodologique. Elles ne répondent cependant pas à l’argument central, qui ne porte pas sur le taux absolu d’erreur mais sur la trajectoire divergente entre précision et grounding d’une version à l’autre.
Par ailleurs, les données internes de Google, citées dans le reportage du New York Times, indiquent que Gemini 3 produit lui-même des informations incorrectes dans 28% des cas lors des tests internes — un chiffre nettement supérieur aux 9% relevés par Oumi. Google précise que les AIO sont plus précises que le modèle nu parce qu’elles s’appuient sur les résultats de recherche en amont, ce qui est plausible. Mais cela déplace le problème plutôt qu’il ne le résout : si la précision factuelle est conditionnée par la qualité des sources indexées, alors la dégradation du grounding documentée entre Gemini 2 et Gemini 3 suggère que cette dépendance aux sources se fragilise à mesure que le modèle gagne en confiance.
Les implications pour le référencement et l’écosystème éditorial
Pour les professionnels du SEO, ce paradoxe a des conséquences directes. Le modèle de référencement éditorial traditionnel repose sur une logique de citation : un contenu bien positionné dans les résultats organiques est susceptible d’être cité comme source par les AIO, ce qui génère une forme de visibilité même sans clic. Cette logique suppose que la citation soit ancrée, c’est-à-dire que le contenu de la source corresponde à l’affirmation que l’AIO en extrait.
Or, si 56% des réponses correctes de Gemini 3 citent des sources qui ne les soutiennent pas pleinement, deux scénarios se dessinent pour un éditeur :
- Son contenu peut être cité même lorsque l’AIO en tire une affirmation inexacte ou déformée, ce qui l’associe à une information erronée sans qu’il en ait le contrôle
- Son contenu peut soutenir une affirmation correcte sans être cité, privant l’éditeur de toute attribution
Dans les deux cas, la promesse implicite du référencement généralisé — être source, c’est être reconnu — se défait. La question posée à l’industrie est de fond : peut-on optimiser pour un système dont le mécanisme de citation est de moins en moins fiable ?
Une donnée complémentaire, issue d’une étude Pew Research citée dans la presse spécialisée, éclaire l’enjeu comportemental : les utilisateurs exposés à un résumé AIO ne cliquent sur les résultats traditionnels que dans 8% des visites, contre 15% pour ceux qui n’en voient pas.
Le volume de trafic perdu par les éditeurs n’est donc pas compensé par une attribution fiable dans les AIO elles-mêmes.
Bibliographie
- Tripp Mickle, Cade Metz et al., How Accurate Are Google’s AI Overviews?, The New York Times, 7 avril 2026
- Frank Landymore, Analysis Finds That Google’s AI Overviews Are Providing Misinformation at a Scale Possibly Unprecedented in the History of Human Civilization, Futurism, 8 avril 2026
- Google AI Overviews deliver millions of errors hourly, analysis suggests, Computing, avril 2026
- Google’s AI Overviews are correct nine out of ten times, study finds, The Decoder, avril 2026
- Google AI Overviews: 90% accurate, yet millions of errors remain, Search Engine Land, avril 2026
- Lewis et al., Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks, arXiv, 2020 — article fondateur sur l’architecture RAG
- Kalai & Vempala, Calibrated Language Models Must Hallucinate, STOC 2024 — démonstration formelle que les hallucinations sont inhérentes aux LLM calibrés