
Le Knowledge Graph de Google existe depuis 2012. Douze ans plus tard, il reste l’un des sujets les moins bien compris de l’écosystème SEO – et l’un des plus stratégiques à mesure que les LLMs prennent de la place dans les parcours de recherche. Construire une présence documentée dans ce graphe n’est pas une option réservée aux grandes marques : c’est un levier accessible, avec des mécanismes précis et des actions concrètes.
Cet article présente ces mécanismes tels qu’ils sont documentés, en distinguant ce qui est officiel, ce qui est cohérent avec les observations terrain, et ce qui reste hypothétique.
Ce qu’est réellement une entité pour Google – et pourquoi ça change tout
L’entité vs le mot-clé : une distinction opérationnelle
Google l’a formulé clairement lors du lancement de son Knowledge Graph en 2012 : l’objectif est de comprendre << things, not strings >>. Cette formulation résume une rupture fondamentale dans la logique de traitement de l’information.
Un mot-clé est une chaîne de caractères. Une entité est un objet d’information unique, identifiable de manière non ambiguë, qui existe indépendamment du document qui le mentionne. << Apple >> est une chaîne. Apple Inc. est une entité. << Paris >> est une chaîne. Paris, capitale de la France, est une entité – distincte des nombreuses autres villes portant ce nom dans le monde.
Cette distinction a des implications opérationnelles directes. Lorsque Google traite une requête sur la base des entités qu’il reconnaît, il peut relier des concepts, des personnes, des lieux et des organisations entre eux, et répondre à des questions complexes sans se limiter à la correspondance lexicale. C’est la base des Knowledge Panels, des featured snippets enrichis, et des réponses directes dans Google Assistant.
Pour un SEO ou un GEO, ça signifie que la visibilité d’une entité n’est plus uniquement une question de ranking de pages – c’est une question de reconnaissance dans une base de données structurée qui alimente une part croissante des surfaces de réponse.
Comment Google reconnaît une entité : les signaux documentés
Google ne publie pas de documentation exhaustive sur son algorithme de reconnaissance d’entités. Ce qui est documenté – par Google Search Central et par l’API Knowledge Graph – permet néanmoins d’identifier les vecteurs principaux.
Le Knowledge Graph Search API, documenté par Google for Developers, retourne des entités en format JSON-LD, conformes aux types schema.org. Il expose un resultScore qui représente le niveau de confiance de Google dans son identification de l’entité pour une requête donnée. Ce score est directement lié à la densité et à la cohérence des signaux disponibles sur l’entité à travers le web.
La documentation de Google Search Central sur le balisage Organization indique explicitement que les données structurées ajoutées à la page d’accueil << can help Google better understand your organization’s administrative details and disambiguate your organization in search results >>. Certaines propriétés, comme iso6523 et naics, sont utilisées << behind the scenes to disambiguate your organization from other organizations >>. Ce n’est pas une inférence – c’est documenté officiellement.
La limite à souligner ici : Wikipedia elle-même le note dans son article sur le Knowledge Graph de Google – << there is no official documentation of how the Google Knowledge Graph is implemented >>. On sait quelles sources alimentent le KG, pas avec précision comment les signaux sont pondérés entre eux.
L’architecture du Knowledge Graph de Google
Sources primaires d’alimentation du KG
Selon la documentation officielle de Google relayée par Wikipedia, le Knowledge Graph s’alimente à partir de << many sources, including the CIA World Factbook and Wikipedia >>. Ce point est confirmé depuis le lancement en 2012.
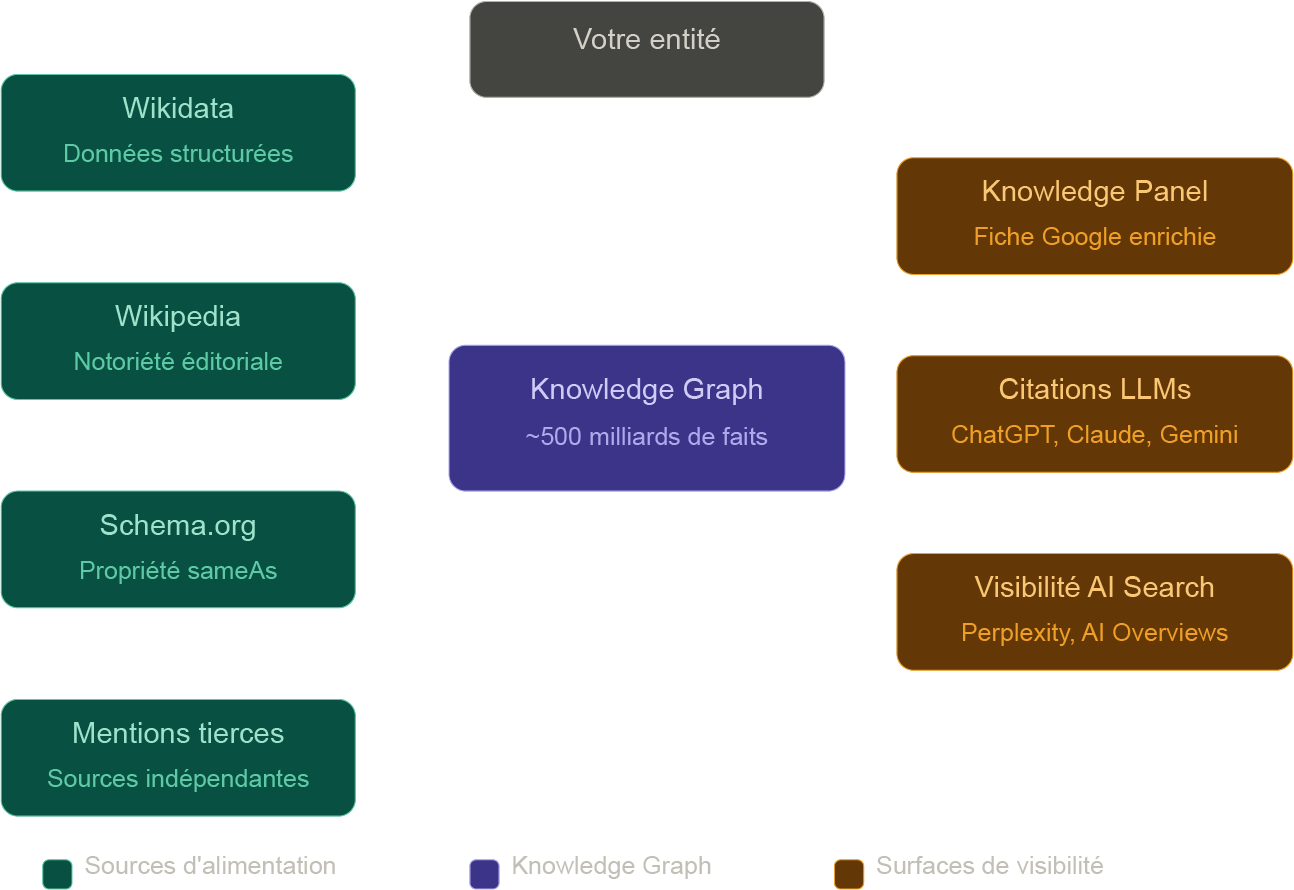
Les données de Google lui-même indiquent que le KG contient aujourd’hui environ 500 milliards de faits concernant environ 5 milliards d’entités. Ces chiffres sont issus des communications officielles de Google et sont repris dans la documentation de l’API Enterprise Knowledge Graph de Google Cloud.
Au-delà de Wikipedia, les sources identifiées comme alimentant le KG incluent Wikidata – pour ses données structurées lisibles par machine -, les profils Google Business Profile pour les entités locales, et les données structurées présentes sur les sites web eux-mêmes via schema.org.
Un point d’importance : Google Search Central documente que l’Organisation schema sur votre page d’accueil influence directement ce que Google affiche dans votre Knowledge Panel – logo, description, liens vers les réseaux sociaux. C’est une connexion directe entre ce que vous publiez en données structurées et ce que le KG retient sur votre entité.
Le rôle de Wikidata comme couche de données structurées
Wikidata est une base de connaissances libre et collaborative, maintenue par la Wikimedia Foundation. Contrairement à Wikipedia qui produit des articles en prose, Wikidata organise l’information sous forme d’énoncés structurés, lisibles par machine : chaque entité (appelée << item >>) reçoit un identifiant unique (de la forme Q12345) et des propriétés qui décrivent ses attributs et ses relations avec d’autres entités.
La documentation de l’API Enterprise Knowledge Graph de Google Cloud elle-même indique : << If you need graphs of interconnected entities, we recommend using data dumps from Wikidata instead >>. Cette recommandation directe dans la documentation officielle de Google illustre la place de Wikidata dans l’écosystème du KG.
Wikidata est accessible à tous. Contrairement à Wikipedia, qui impose des critères de notoriété stricts et un processus éditorial communautaire exigeant, Wikidata permet de créer un item pour n’importe quelle entité réelle, à condition que celle-ci soit identifiable de manière non ambiguë. Un item Wikidata ne requiert pas de notoriété au sens encyclopédique – il requiert une existence vérifiable.
C’est la raison pour laquelle, pour de nombreuses entités qui ne satisfont pas encore les critères Wikipedia, Wikidata constitue le point d’entrée le plus accessible dans l’écosystème du Knowledge Graph.
Wikipedia : conditions d’éligibilité et limites
Wikipedia fonctionne sur un principe de notoriété documentée, tel que défini dans ses directives officielles (WP:N et WP:NCORP). Une organisation est présumée notable si elle a fait l’objet d’une << significant coverage in multiple reliable secondary sources that are independent of the subject >>. Les directives précisent que ces sources doivent être indépendantes, secondaires et fiables – communiqués de presse, sites officiels et contenus produits par l’organisation elle-même sont exclus.
Pour les entreprises, le seuil est particulièrement élevé selon les directives Wikipedia pour les organisations et entreprises (WP:NCORP) : le contenu des sources doit traiter l’organisation en profondeur, pas simplement la mentionner en passant. Plusieurs articles substantiels dans des médias indépendants de référence sont nécessaires pour établir la notoriété.
Ce seuil a plusieurs conséquences pratiques. D’abord, Wikipedia est un indicateur retardé de notoriété : une entité n’y apparaît qu’une fois que la couverture médiatique indépendante existe. Ensuite, tenter de créer une page Wikipedia pour une entité qui ne remplit pas encore ces critères est contre-productif – la page sera supprimée et le compte de l’auteur potentiellement signalé si un conflit d’intérêts non déclaré est détecté. Les directives Wikipedia interdisent explicitement l’édition non déclarée rémunérée (WP:PAID).
La limite opérationnelle est donc claire : Wikipedia ne s’anticipe pas, elle se mérite. La stratégie correcte consiste à construire d’abord la couverture indépendante, puis à envisager une page Wikipedia lorsque les sources existent.
Construire une présence documentée : les leviers actionnables
La fiche Knowledge Panel : déclencheurs et optimisation
Le Knowledge Panel est généré automatiquement par Google lorsqu’il dispose de suffisamment d’informations sur une entité. La documentation officielle de Google (support.google.com/knowledgepanel) est explicite : << Knowledge Panels are created automatically by Google Search Algorithm when there is enough information available on the open web >>. Google ne fournit pas de critères précis sur le seuil de déclenchement – c’est une limite documentée.
En revanche, deux actions sont officiellement documentées par Google pour les entités qui disposent déjà d’un Knowledge Panel.
La première est la revendication du panel. Si vous êtes le sujet ou le représentant officiel de l’entité, vous pouvez revendiquer le panel via la Search Console ou un profil social lié. Cette revendication permet de suggérer des modifications (logo, description, liens).
La seconde est le balisage Organization sur votre site. La documentation Google Search Central indique que ce balisage aide Google à << disambiguate your organization in search results >> et influence directement les informations affichées dans le Knowledge Panel. Les propriétés les plus impactantes sont name, url, logo, sameAs, foundingDate et description.
Wikidata : créer et enrichir un item
La création d’un item Wikidata suit un processus documenté sur Wikidata.org. Les étapes essentielles sont les suivantes.
Vérifier d’abord l’existence d’un item. Rechercher l’entité dans Wikidata avant toute création pour éviter les doublons, qui nuisent à la cohérence du graphe.
Créer l’item avec un label (le nom de l’entité), une description courte et non ambiguë, et si nécessaire des alias (variantes du nom). L’item reçoit automatiquement un identifiant unique (Qxxxxx).
Ajouter les propriétés pertinentes. Pour une organisation, les propriétés essentielles incluent : P31 (instance de), P18 (image), P571 (date de fondation), P159 (siège social), P856 (site officiel), P17 (pays), P452 (secteur d’activité). Chaque propriété doit être accompagnée de sources référencées.
Lier l’item Wikidata à l’article Wikipedia correspondant (si celui-ci existe) via les << sitelinks >>. Cette connexion est bidirectionnelle dans l’écosystème Wikimedia et renforce la cohérence de l’entité entre les deux plateformes.
Maintenir l’item à jour. Un item Wikidata obsolète – avec une adresse incorrecte ou un site web mort – envoie des signaux de confiance négatifs.
Les mentions tierces comme signal de corroboration
La cohérence des informations sur une entité à travers des sources tierces est un signal de corroboration pour le Knowledge Graph. Les plateformes couramment identifiées dans ce rôle incluent LinkedIn, Crunchbase, les annuaires sectoriels reconnus, et les bases de données officielles (numéros d’enregistrement légaux, brevets, publications académiques).
Ce n’est pas un signal documenté officiellement par Google – c’est une inférence cohérente avec la logique de corroboration des graphes de connaissances, et une pratique convergente dans la communauté SEO. Elle doit être traitée comme telle : une hypothèse opérationnelle validée par l’observation, pas un fait certifié.
Ce qui est en revanche documenté : la propriété sameAs de schema.org permet de lier explicitement votre entité à ses profils sur des plateformes tierces. Un exemple de la documentation Google Search Central montre l’usage de sameAs avec des URLs de profils externes dans le balisage Organization. L’objectif est de permettre à Google de réconcilier les informations sur votre entité issues de différentes sources.
Les données structurées comme pont entre votre site et le KG
La documentation de Google Search Central sur l’Organization schema constitue la référence officielle pour cette section. Google recommande d’implémenter le balisage en JSON-LD (format recommandé) sur la page d’accueil au minimum.
Les propriétés documentées comme jouant un rôle de désambiguïsation incluent :
sameAs : liste d’URLs pointant vers des profils faisant autorité (Wikidata, LinkedIn, profils sociaux vérifiés). C’est le pont explicite entre votre site et les entités reconnues dans des bases de données tierces.
@id : identifiant unique de l’entité dans votre propre graphe de données structurées. Il doit être cohérent entre toutes les pages de votre site qui référencent cette entité.
iso6523Code et naics : codes d’identification légaux et sectoriels. Google Search Central note explicitement que ces propriétés sont utilisées << behind the scenes to disambiguate your organization >>.
knowsAbout : propriété permettant de déclarer les domaines d’expertise ou sujets associés à l’entité. C’est distincte de sameAs – elle ne pointe pas vers une entité identique, mais vers des sujets que l’entité maîtrise.
Un cas documenté par Schema App sur un expérience client sur 85 jours a montré une augmentation de 46 % des impressions et 42 % des clics pour des requêtes non brandées après implémentation du linking d’entités via sameAs et spatialCoverage. Cette donnée provient d’une étude de cas publiée par Schema App, pas d’une recherche académique indépendante – elle doit être traitée comme un résultat observé, potentiellement non généralisable.
Entités et LLMs : la reconnaissance d’entité dans les moteurs génératifs
Comment les LLMs construisent leur représentation d’une entité
Les LLMs ne fonctionnent pas avec une base de données d’entités structurée comme le Knowledge Graph de Google. Ils construisent des représentations d’entités à partir de l’ensemble de leur corpus d’entraînement. Pour une entité donnée, le modèle agrège les cooccurrences, les contextes d’utilisation, et les attributs mentionnés dans les textes qui la décrivent.
Deux mécanismes distincts sont à l’oeuvre, selon la terminologie établie par les études sur les LLMs et la GEO. La << connaissance paramétrique >> est ce que le modèle a intégré lors de l’entraînement – c’est statique, figé au moment du cutoff du modèle. La connaissance issue du RAG (Retrieval-Augmented Generation) est récupérée en temps réel lors de la génération de la réponse, via un index web ou des sources externes.
Pour la connaissance paramétrique, la qualité et la densité de la présence documentée d’une entité dans le corpus d’entraînement détermine directement la richesse de sa représentation dans le modèle. Une entité bien documentée sur Wikipedia, Wikidata, et dans des sources de référence a davantage de chances d’être représentée avec précision que celle dont les informations sont éparses ou contradictoires.
Ce point est cohérent avec la logique des LLMs telle qu’elle est documentée dans la littérature académique sur les named entity recognition (NER) tasks – il n’existe pas à ce jour de déclaration officielle d’OpenAI, Anthropic ou Google précisant exactement comment leurs modèles pondèrent Wikipedia ou Wikidata dans la construction de leurs représentations d’entités.
Ce que Wikidata et Wikipedia apportent spécifiquement aux LLMs
Plusieurs travaux de recherche documentent l’utilisation de Wikidata et Wikipedia dans les pipelines de traitement des entités par les LLMs.
Une étude publiée sur ResearchGate (novembre 2024) – << Entity Linking for Wikidata using Large Language Models and Wikipedia Links >> – documente comment les liens Wikipedia sont utilisés comme signal de supervision distante pour l’entraînement de systèmes de reconnaissance d’entités. Ce travail illustre la place structurelle de Wikipedia et Wikidata comme bases de référence dans les pipelines NER des LLMs.
Google DeepMind a publié en 2024 un article sur la reconnaissance d’entités visuelles à grande échelle (arXiv:2410.23676) qui utilise Wikipedia comme source de référence pour les entités dans les tâches de reconnaissance d’images. Ce travail confirme que Wikipedia reste une source de référence primaire pour les systèmes d’IA de Google sur les tâches de reconnaissance d’entités.
Pour les systèmes RAG comme Perplexity ou ChatGPT Search, la présence d’une entité dans des sources récentes, structurées et fréquemment citées reste le principal levier de visibilité. Une entité bien définie dans Wikidata, liée à un article Wikipedia et mentionnée de manière cohérente sur des plateformes tierces, présente un profil favorable à la reconnaissance et à la citation par ces systèmes.
Hypothèse opérationnelle à noter : la corrélation entre présence dans le Knowledge Graph de Google et visibilité dans les LLMs est logiquement plausible, mais elle n’a pas fait l’objet de mesure directe et publiée à ce jour. Les deux systèmes partagent des sources communes (Wikipedia, Wikidata) sans que l’un conditionne nécessairement l’autre.
Les limites à ne pas ignorer
Ce qu’on ne contrôle pas dans le Knowledge Graph
Google est explicite sur un point : vous ne contrôlez pas directement le Knowledge Graph. Vous pouvez envoyer des signaux, mais la décision de créer un Knowledge Panel, d’y inclure une information ou de l’en retirer appartient à Google.
La documentation officielle de Google (support.google.com/knowledgepanel) indique que les modifications suggérées après revendication du panel doivent être accompagnées de << credible sources >> – sans garantie d’acceptation. Le délai de prise en compte n’est pas documenté.
Une limite importante concerne les informations incorrectes dans le KG. Si Google a agrégé des informations erronées sur votre entité à partir de sources tierces – une date de fondation incorrecte, une description inexacte – corriger ces informations passe par la revendication du panel et des suggestions appuyées sur des sources, sans garantie de résultat à court terme.
Enfin, Wikipedia elle-même l’indique : << There is no official documentation of how the Google Knowledge Graph is implemented >>. Toute affirmation sur la pondération exacte des signaux dans le KG reste une inférence, pas un fait documenté.
Les risques de l’entity building mal conduit
Trois risques méritent d’être documentés explicitement.
La création de pages Wikipedia non conformes. Tenter de créer une page Wikipedia pour une entité qui ne remplit pas les critères de notoriété se solde par une suppression. Dans le cas où un conflit d’intérêts non déclaré est identifié (un salarié ou un prestataire rémunéré créant la page), le compte peut être bloqué et la page protégée contre une recréation. Les directives Wikipedia sur l’édition rémunérée (WP:PAID) exigent une déclaration explicite de tout conflit d’intérêts.
L’incohérence entre les sources. Si le nom de l’entité, sa date de fondation, son URL officielle ou son secteur d’activité diffèrent entre Wikidata, LinkedIn, Crunchbase et votre balisage schema.org, ces incohérences fragmentent le signal d’entité. La règle de cohérence s’applique à tous les attributs stables de l’entité.
La suroptimisation du balisage schema.org. Google Search Central avertit contre le << misleading markup >> – l’utilisation de propriétés pour décrire autre chose que ce que la page contient réellement. Un balisage Organization qui déclare des attributs non vérifiables ou exagérés peut être ignoré, voire pénaliser la confiance accordée au reste du balisage.
Ce que ça change dans la pratique
Construire une présence documentée dans le Knowledge Graph n’est pas une opération ponctuelle – c’est un processus continu d’alignement entre ce que vous êtes, ce que vos sources tierces disent de vous, et ce que vos données structurées déclarent.
L’ordre logique est le suivant.
Commencer par Wikidata : créer ou revendiquer un item avec les propriétés essentielles, sourcées, cohérentes avec votre site officiel. C’est le signal le plus accessible et l’un des plus directement lus par les systèmes automatiques.
Implémenter le balisage Organization en JSON-LD sur la page d’accueil, en incluant sameAs pointant vers Wikidata, LinkedIn, et tout profil vérifié pertinent. S’appuyer sur la documentation officielle Google Search Central pour les propriétés.
Construire la couverture media indépendante qui constitue le prérequis de notoriété pour Wikipedia – et n’envisager une page Wikipedia qu’une fois ce prérequis satisfait, en respectant les directives WP:N et WP:NCORP.
Auditer régulièrement la cohérence des informations sur votre entité à travers toutes les sources. Un item Wikidata avec un site web obsolète ou un profil LinkedIn avec une description divergente de votre page d’accueil sont des signaux négatifs.
Vérifier votre présence dans le Knowledge Graph via l’API publique (kgsearch.googleapis.com) pour confirmer que Google reconnaît votre entité et avec quel niveau de confiance (resultScore). C’est un outil de diagnostic disponible, documenté, et gratuit dans sa version de base.
Sources
- Google for Developers – Knowledge Graph Search API – (mis à jour avril 2024)
- Google Cloud Documentation – Enterprise Knowledge Graph overview
- Google Search Central – Organization structured data
- Google Knowledge Panel Help – How Google’s Knowledge Graph works
- Wikipedia – Google Knowledge Graph
- Wikipedia – Notability (organizations and companies)
- Wikipedia – Notability (general guideline)
- Vespa.ai – How Perplexity uses Vespa.ai – (2025)
- Schema App – Impact of Scaling Entity Linking
- Google Search Central – Schema.org sameAs property
- ResearchGate / arXiv – Entity Linking for Wikidata using Large Language Models and Wikipedia Links – (novembre 2024)
- Google DeepMind / arXiv – Web-Scale Visual Entity Recognition: An LLM-Driven Data Approach – (2024)
- The Digital Bloom – 2025 AI Visibility Report: How LLMs Choose What Sources to Mention – (décembre 2025)
- Will Scott – When should I use sameAs versus knowsAbout in Schema.org markup – (juillet 2025)