

Pendant très longtemps, Google n’a pas réellement montré le meilleur exemple concernant sa gestion du « standard » robots.txt. Ils ont notamment supporté des fonctionnalités « made in Google » absolument pas supportées par les autres moteurs : comme les caractères joker dans les urls, ou les directives noindex.
Puis Gary Illyes s’est saisi du problème, et a pris le lead chez Google mais aussi pour l’ensemble des moteurs pour revisiter le concept du robots.txt pour en faire véritablement un standard, respecté par tout le monde, y compris dans la manière d’analyser le contenu des robots.txt
Nous avions déjà eu l’occasion de rappeler les changements qui étaient intervenus à la suite de ce virage chez Google dans la prise en compte des fonctionnalités des robots.txt :
De nouveaux détails viennent d’être précisés dans la documentation
Les changements notables dans la documentation sont des ajouts sur la façon de gérér les robots.txt correspondant à des hosts définis par :
- des adresses IP
- des IDN
- des ports
Jusqu’ici, les choses étaient claires uniquement pour des urls classiques. Ces précisions sont les bienvenues, car elles permettent de prédire si une url sera prise en compte ou non dès lors qu’elle contient des éléments plus exotiques
Urls utilisant des adresses IP
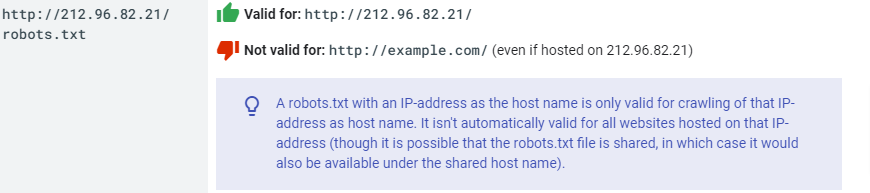
Concrètement, si un site web est appelable via une adresse IP, les directives du robots.txt ne fonctionneront que sur les urls commençant par cette adresse IP. Et ceci, même s’il existe un nom de domaine canonique (domaine.com) pointant vers cette adresse IP.
Urls utilisant des IDN (noms de domaines internationalisés, avec accents)

Si le domaine est « accentué », alors le robots.txt n’est valide que sur la version accentuée (mais aussi la version Punycode du même domaine, qui est en fait la « vraie » syntaxe utilisée par les serveurs de noms). Par contre, et c’est logique, les directives du robots.txt ne fonctionnent pas sur la version non accentuée, car c’est un nom de domaine totalement différent (même si les deux se ressemblent).
Support des hosts comportement des mentions de ports web
http://example.com:80/robots.txt | Valid for:http://example.com:80/http://example.com/Not valid for: http://example.com:81/Standard port numbers (80 for HTTP, 443 for HTTPS, 21 for FTP) are equivalent to their default host names. See also [portnumbers]. |
http://example.com:8181/robots.txt | Valid for: http://example.com:8181/Not valid for: http://example.com/Robots.txt files on non-standard port numbers are only valid for content made available through those port numbers. |
Si votre site comporte un port dans son url, alors c’est un peu plus subtil.
Si vous mentionnez un port standard, qui est redondant avec le protocole utilisé, alors, le robots.txt sera valide que la syntaxe avec ou sans port soit utilisée. Les ports standard sont : 80 pour http, 443 pour https, et 21 pour FTP
Si par contre vous utilisez un port « exotique », alors le moteur considérera que c’est un autre host. Dans la pratique c’est souvent le cas, la mention d’un port différent permet d’envoyer les requêtes vers un serveur web différent.
Et si on utilise le port 8080 me direz-vous ? Et bien, c’est aussi un port web standard, mais c’est un port différent de 80, donc : le robots.txt dont l’url est http://example.com:80/robots.txt ne sera pas valide pour le host http://example.com:8080/
La page de référence est ici :
https://developers.google.com/search/docs/advanced/robots/robots_txt?hl=fr