

Définition de Allow: :
 Allow: est une directive utilisée dans les fichiers robots.txt et proposée par Google et Bing. Elle permet d’autoriser l’exploration par les robots des moteurs de recherche d’une page ou d’un répertoire complet sur un site web.
Allow: est une directive utilisée dans les fichiers robots.txt et proposée par Google et Bing. Elle permet d’autoriser l’exploration par les robots des moteurs de recherche d’une page ou d’un répertoire complet sur un site web.
Le fichier robots.txt permet d’indiquer aux robots des moteurs de recherche un certain nombre de directives sur leur comportement lorsqu’ils crawlent un site web. La directive Allow: permet, contrairement au Disallow:, d’autoriser cette exploration. Mais attention, elle n’est pas obligatoirement standard !
La directive Allow: permet, dans un fichier robots.txt, d’indiquer aux robots comme Googlebot ou Bingbot ce qu’ils doivent faire lors de leur exploration et plus précisément les zones de votre site où ils peuvent aller (le plus souvent en conjonction avec une directive Disallow: qui, elle, interdit le crawl).
La syntaxe de cette directive est la suivante :
Allow: [path]
Où [path] indique le début (ou une règle) de l’URL des pages à crawler.
Voici quelques exemples (pour un site de type https://www.exemple.com/) :
Allow: /
Equivalent de Disallow: (le site peut être entièrement crawlé, sans limite).
Disallow: /
Allow: /blog
Tout le site sera interdit au crawl, sauf le répertoire https://www.exemple.com/blog
Disallow: blog
Allow: blog/articles
Tout le répertoire blog sera interdit au crawl, sauf le sous-répertoire https://www.exemple.com/blog/articles
Etc.
Attention cependant : la directive Allow:, définie en 2008, si elle est comprise par Google et Bing, n’est pas totalement standard et pourra ne pas être comprise par certains moteurs plus « exotiques ».
D’autre part, l’utilisation conjuguée et parfois complexe des directives Disallow: et Allow: (notamment avec des jokers comme * ou $) peut rendre l’interprétation des règles fournies assez difficile et peut générer des erreurs de crawl. L’utilisation de la directive Allow: est donc assez sensible. Réflexion obligatoire avant de l’utiliser !
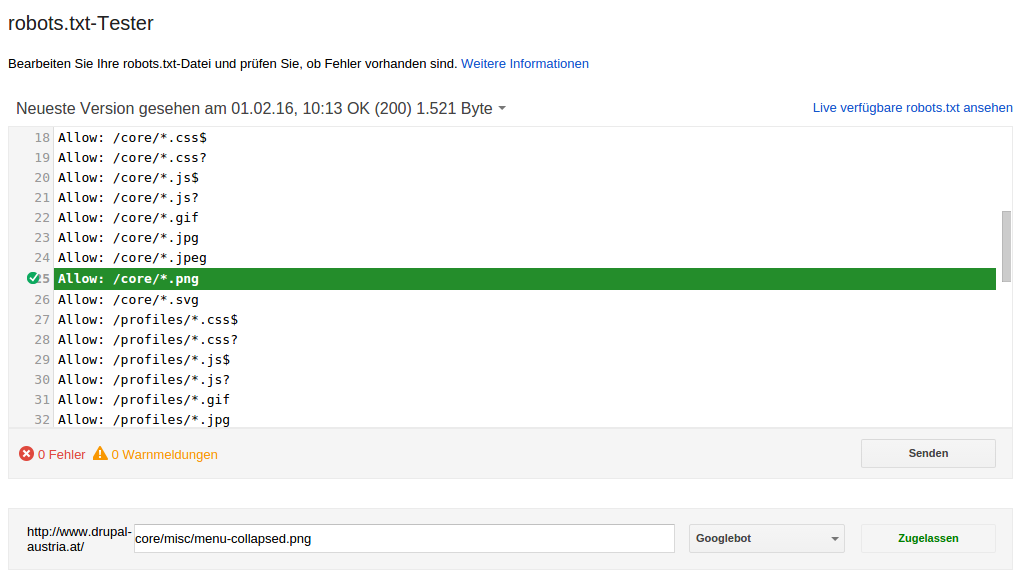 Exemple de fichier robots.txt contenant des directives Allow: (Source). |
Voici également quelques liens pour aller plus loin sur le sujet :
- Robots.txt pour Google / Googlebot
- Make sure Googlebot is not blocked (Google)
- Créer un fichier robots.txt (Google)
- Les petites subtilités du fichier robots.txt qui peuvent faire mal (YaPasDeQuoi)
Et 2 vidéos de Matt Cutts et Abondance qui vous en disent un peu plus sur la façon dont fonctionnent les robots des moteurs et le fichier robots.txt :
Spiders, Robots, Crawlers : comment ça marche ? (Abondance)
How Search Works (Google, Matt Cutts)