
Pendant des années, les éditeurs et les spécialistes SEO ont traité Google Discover comme une boîte noire monolithique. Un article performe, un autre non, et personne ne sait vraiment pourquoi. Deux travaux récents viennent bousculer cette vision : la décompilation de l’application Google Android par le consultant SEO turc Metehan Yesilyurt (metehan.ai), et l’analyse de 42 millions de cartes Discover menée par la plateforme française 1492.vision (Sylvain Deaure et Damien Andell). Leur conclusion convergente : Discover n’est pas un flux uniforme, mais un assemblage de circuits de sélection distincts, chacun avec sa propre logique, sa propre portée et ses propres règles.
Ce dossier fait le point sur ces découvertes, en distinguant ce qui est solidement établi de ce qui relève de l’interprétation, et en tirant les recommandations actionnables pour les éditeurs.
D’où viennent ces données ?
Tout commence avec un travail de reverse engineering (rétro-ingénierie logicielle) mené par Metehan Yesilyurt sur l’APK Android de l’application Google. L’APK, c’est le fichier d’installation d’une application Android : en le décompilant, on peut lire une partie du code source et identifier des noms de variables, des constantes et des endpoints de communication. Yesilyurt a ainsi extrait 87 498 classes Java, dont 95,5 % sont obfusquées (rendues illisibles intentionnellement par Google). Dans les 4,5 % restants, il a identifié 13 « cluster types » : des étiquettes attribuées à chaque carte du feed Discover, qui indiquent par quel mécanisme de sélection le contenu a été retenu.
L’avertissement de Yesilyurt est important à garder en tête : tout ce qu’il décrit reflète l’état du code client à un instant donné. Google peut modifier les systèmes côté serveur à tout moment, sans mise à jour de l’application.
De son côté, 1492.vision a collecté des données à une tout autre échelle. La plateforme a mobilisé des centaines d’appareils (émulateurs ou physiques) scrollant le feed Discover en continu pendant trois mois (décembre 2025 à février 2026), avec un panel réparti à environ 75 % sur le marché français et 25 % sur l’anglophone. À partir de ces données, 1492.vision identifie 20 clusters, soit 7 de plus que la liste publiée par Yesilyurt. Les noms supplémentaires (content, aura, paginationpanoptic, relatedcontentruby, creatorcontent, shoppinginspiration, entre autres) ne figurent pas dans la publication originale de Yesilyurt, et 1492.vision ne documente pas publiquement leur origine exacte.
Point de vocabulaire critique. Yesilyurt parle de « cluster types » : des étiquettes apposées sur les cartes du feed. 1492.vision a renommé ces étiquettes en « pipelines », un terme qui suggère des circuits de traitement parallèles et indépendants. Ce n’est pas la même chose. Un cluster type peut être une simple classification appliquée après coup sur un contenu déjà sélectionné. Un pipeline implique un chemin de traitement complet, de l’ingestion à la distribution. La réalité est probablement hybride : certains clusters (comme feedads ou neoncluster) correspondent vraisemblablement à de vrais circuits distincts, tandis que d’autres sont plutôt des étiquettes de classification sur un contenu partagé. Pour le reste de cet article, nous utiliserons le terme « cluster », plus fidèle à ce que le code révèle.
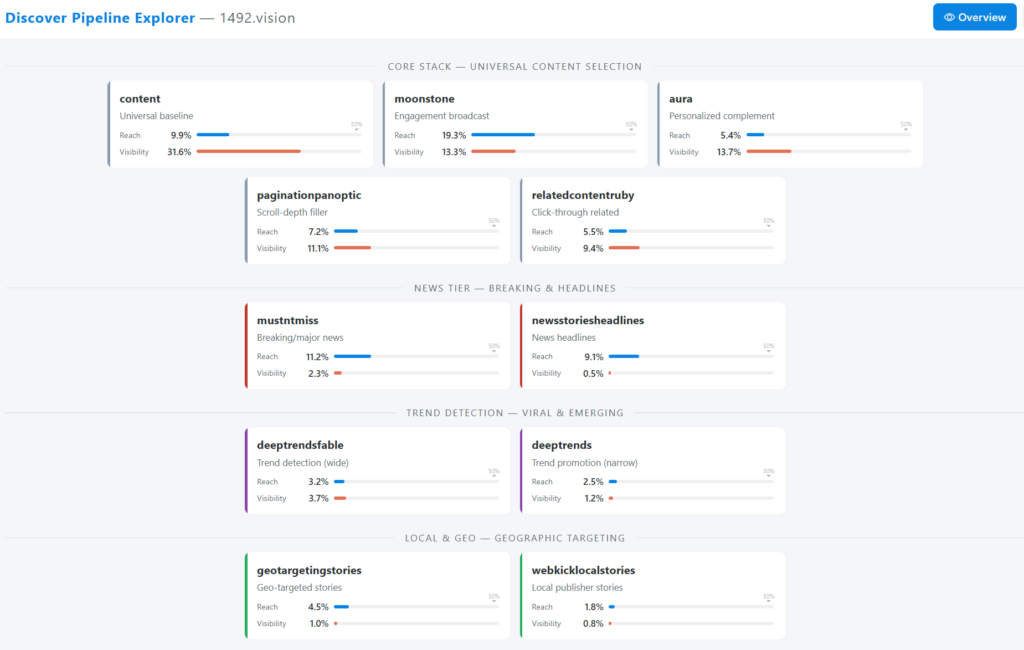
L’équipe de 1492.vision a créé une dataviz pour explorer les données qu’ils ont collectés sur les pipelines / clusters. Vous pouvez la consulter ici https://1492.vision/interactive/xpl/.
Les 20 clusters : cartographie complète
Le tableau ci-dessous synthétise les données publiées par 1492.vision pour les marchés français et anglophone. Le reach (portée) indique le pourcentage d’appareils du panel qui ont vu au moins une carte de ce cluster. Le cards/day (cartes par jour) mesure le volume quotidien moyen de cartes servies.
| Cluster | Catégorie | Rôle | Reach FR | Reach EN | Cards/j FR | Cards/j EN |
|---|---|---|---|---|---|---|
| content | core | Socle universel de sélection | 9,9 % | 8,8 % | 758 | 809 |
| moonstone | core | Broadcast engagement | 19,3 % | 9,4 % | 319 | 184 |
| aura | core | Complément personnalisé | 5,4 % | 4,8 % | 328 | 206 |
| paginationpanoptic | core | Remplissage en scroll profond | 7,2 % | 6,2 % | 267 | 131 |
| relatedcontentruby | core | Articles liés post-clic | 5,5 % | 4,8 % | 224 | 158 |
| mustntmiss | news | Actualité brûlante | 11,2 % | 7,3 % | 54 | 12 |
| newsstoriesheadlines | news | Gros titres | 9,1 % | 10,6 % | 13 | 10 |
| deeptrendsfable | trend | Détection de tendances (large) | 3,2 % | 3,4 % | 88 | 11 |
| deeptrends | trend | Promotion de tendances (ciblé) | 2,5 % | 3,2 % | 29 | 5 |
| geotargetingstories | local | Contenus géolocalisés | 4,5 % | 4,9 % | 24 | 17 |
| webkicklocalstories | local | Éditeurs locaux | 1,8 % | 2,8 % | 18 | 7 |
| astria | niche | Contenus verticaux/niche | 4,7 % | 5,7 % | 61 | 40 |
| creatorcontent | social | Contenus créateurs/réseaux | 6,0 % | 6,7 % | 44 | 96 |
| freshvideos | social | Vidéo récente | 2,9 % | 7,1 % | 9 | 104 |
| neoncluster | social | Cluster YouTube | 0,0 % | 13,0 % | 0 | 107 |
| dvrc | perso | Articles liés au profil | 1,1 % | 2,6 % | 3 | 20 |
| userpersonascontent | perso | Matching par persona | 1,9 % | 2,4 % | 5 | 2 |
| shoppinginspiration | commercial | Cartes produits/shopping | 19,7 % | 13,1 % | 76 | 68 |
| feedads | commercial | Publicités intégrées | 23,6 % | 58,4 % | 75 | 264 |
| discover_ai_summary | IA | Résumés AI Overview | 0,0 % | 3,5 % | 0 | 26 |
Plusieurs observations sautent aux yeux.
- Moonstone est le cluster éditorial le plus puissant en France avec 19,3 % de reach, soit environ un utilisateur sur cinq.
- Shoppinginspiration atteint une portée comparable (19,7 %), révélant le poids insoupçonné du commerce dans le feed.
- Et feedads domine le reach global avec 23,6 % en FR et 58,4 % en EN : le feed anglophone est plus de deux fois plus monétisé que le français.
Ce que les données révèlent sur le fonctionnement de Discover
Un système à deux dimensions.
Les données montrent que les clusters et les types de cartes fonctionnent comme deux axes indépendants. Le cluster indique pourquoi un contenu a été sélectionné (tendance, engagement, géolocalisation, etc.). Le type de carte indique comment il est affiché : type 1 pour les articles texte, type 2 pour les vidéos YouTube, type 6 pour les AI Overviews (résumés générés par l’IA de Google). Un même cluster peut servir plusieurs types de cartes. Par exemple, mustntmiss contient 28,3 % de cartes AI Overview en anglais, mais reste massivement textuel en français.
Le multi-labeling est la norme, pas l’exception. C’est l’un des enseignements les plus contre-intuitifs. En France, 58 % des URLs apparaissent dans deux clusters ou plus. Certaines URLs ont été observées dans jusqu’à 14 clusters différents. Les cinq clusters « core » (content, moonstone, aura, paginationpanoptic, relatedcontentruby) partagent massivement des URLs entre eux : la paire aura/content partage à elle seule 356 399 URLs. Cela plaide fortement pour l’hypothèse des étiquettes multiples appliquées sur un même contenu, plutôt que pour des circuits de sélection hermétiquement séparés.
En revanche, neoncluster et feedads ont très peu de co-occurrence avec les autres clusters : ce sont probablement de vrais circuits distincts, ce qui est logique pour un flux publicitaire et un flux 100 % YouTube.
Des relations séquentielles entre clusters. Trois parcours temporels ont été identifiés dans les données. Un contenu apparaît d’abord dans creatorcontent, puis dans freshvideos environ 15 heures plus tard, puis dans neoncluster 8 heures après. Autre chemin : deeptrendsfable vers deeptrends avec un écart de 21 heures et un taux de passage de 27 %. Autrement dit, certains clusters fonctionnent comme des étapes de maturation : un contenu peut monter dans la hiérarchie de distribution au fil du temps.
France vs monde anglophone : deux Discover différents
Les données de 1492.vision confirment un constat que les éditeurs français soupçonnaient : le Discover français et le Discover anglophone ne se comportent pas du tout de la même manière. Les écarts sont structurels, pas marginaux.
Le flux français est massivement textuel. La vidéo représente moins de 5 % du feed FR, contre 13 % en EN (neoncluster seul). Neoncluster, qui est 100 % YouTube, est quasiment absent en France : 36 cartes en trois mois, contre 454 000 en anglais. Pour les éditeurs français, cela signifie que le contenu texte reste le format roi sur Discover France, alors que les stratégies anglophones intégrant YouTube ont un levier supplémentaire.
Les sources sociales sont inversées. Dans le cluster creatorcontent, les contenus issus de X (ex-Twitter) représentent 80 % du volume en français, contre seulement 27 % en anglais où YouTube domine avec 73 %. Cette inversion complète reflète probablement les habitudes de consommation et l’écosystème de créateurs propres à chaque marché.
Les AI Overviews sont absentes en France. Le type de carte « AI Overview » (type 6) est à 0,0 % dans l’intégralité des clusters FR. En anglais, il pénètre jusqu’à 28,3 % du cluster mustntmiss. Cette donnée est cohérente avec le calendrier de déploiement de Google : les AI Overviews n’ont pas encore été activées sur Google France au moment de la collecte.
Moonstone pèse deux fois plus en France. Avec 19,3 % de reach en FR contre 9,4 % en EN, moonstone est le canal de broadcast éditorial dominant en France. En anglais, son poids est dilué par la concurrence de neoncluster et du volume de feedads. Pour les éditeurs français, performer dans moonstone est donc un levier de visibilité proportionnellement plus important.
Le multi-labeling a plus de levier en France. 58 % des URLs françaises apparaissent dans 2 clusters ou plus, contre 37 % en anglais. Cela signifie qu’en France, un contenu qui réussit à entrer dans le système Discover a plus de chances d’être redistribué par plusieurs mécanismes différents.
Infographie montrant comment les clusters sont assemblés dans le flux Discover : c’est intéractif, un clic sur un cluster montre où il est utilisé dans le flux à droite
Ce qu’il faut prendre avec des pincettes
Aussi passionnantes soient-elles, ces données comportent des limites méthodologiques qu’il serait imprudent d’ignorer.
Trois mois, c’est un snapshot. Les tendances observées entre décembre 2025 et février 2026 peuvent très bien correspondre à des tests A/B temporaires de Google. Le déclin apparent de moonstone et l’explosion de creatorcontent pourraient s’inverser au trimestre suivant. Google mène en permanence environ 150 tests serveur simultanés sur le feed Discover, comme l’a documenté Yesilyurt dans le code.
Corrélation n’est pas causalité. Observer qu’un type de contenu se retrouve majoritairement dans un cluster donné ne prouve pas le mécanisme de sélection. Dire que « moonstone sélectionne le contenu à fort engagement » est une inférence plausible, pas un fait vérifié dans le code.
Enfin, le conflit d’intérêts mérite d’être signalé sans que cela invalide les travaux. 1492.vision est un outil commercial de monitoring Discover. Ses conclusions orientent naturellement vers un besoin de « monitoring continu », c’est-à-dire exactement ce que la plateforme vend. Cela ne rend pas les données fausses, mais cela justifie un regard critique sur l’interprétation qui en est faite.
Ce que les éditeurs peuvent faire dès maintenant
Au-delà de la cartographie, ces travaux permettent de commencer à dégager des recommandations concrètes pour les éditeurs, même si, par manque de recul, la moisson de « pour action » actionnables reste encore maigre.
Penser en scénarios, pas en formule unique.
C’est l’apport le plus fondamental. Au lieu de chercher « la » recette Discover, il faut raisonner en fonction du type de contenu : actualité chaude (mustntmiss, newsstoriesheadlines), tendance émergente (deeptrendsfable, deeptrends), contenu de niche à forte affinité (astria), contenu à portée locale (geotargetingstories, webkicklocalstories), ou contenu « best-of » à large diffusion (moonstone). Chaque scénario a ses propres signaux de sélection.
Attention aux prérequis techniques et au bon emploi des données structurées.
Le code décompilé par Yesilyurt confirme la chaîne de priorité des métadonnées : Schema.org JSON-LD en premier, puis og:title, puis twitter:title, puis title générique. Même logique pour les images. Ne pas implémenter de balisage JSON-LD, c’est se placer volontairement sur le chemin de fallback. L’image hero doit faire au minimum 1 200 pixels de large pour déclencher le format carte large.
Surveiller la balise article:content_tier.
Le code révèle trois valeurs possibles : « free », « metered » et « locked ». Les contenus metered et locked sont identifiés comme paywall. Si votre site utilise un paywall, vérifiez que la valeur déclarée correspond à votre modèle réel : une incohérence peut déclencher un événement d’avertissement dans le système de Google.
Éviter les meta tags bloquants.
Les tags notranslate et nopagereadaloud provoquent un arrêt complet du pipeline de traitement avec exception. Si ces tags sont présents sur vos pages par héritage technique, ils bloquent potentiellement votre éligibilité à Discover.
Viser le multi-cluster plutôt que le pic unique. Puisque 58 % des URLs françaises apparaissent dans 2 clusters ou plus, un contenu qui combine plusieurs signaux (fraîcheur, pertinence thématique, engagement potentiel) a structurellement plus de chances d’être redistribué par plusieurs mécanismes. La durée de vie du contenu shopping en France (3,7 jours en moyenne contre 2,5 en anglais) montre aussi que les contenus persistants ont un avantage sur le marché français.
Pour les éditeurs locaux : un boulevard existe. Les clusters geotargetingstories et webkicklocalstories, bien que modestes en volume, représentent des circuits de distribution dédiés aux contenus géolocalisés. Les éditeurs de presse régionale ou les médias locaux disposent d’un accès à Discover qui ne dépend pas de la concurrence frontale avec les grands médias nationaux.
Ne pas transposer les recettes anglophones.
Les différences structurelles entre les deux marchés sont trop importantes. La domination de YouTube en anglais, l’absence d’AI Overviews en France, le poids relatif de moonstone et l’inversion des sources sociales dans creatorcontent rendent les stratégies cross-market inopérantes. Ce qui fonctionne pour un média américain ne s’applique pas au marché français.
Ce que ces travaux changent dans la compréhension de Discover
Le travail conjoint de Yesilyurt et de 1492.vision marque un tournant dans la compréhension de Google Discover. Pour la première fois, la communauté SEO dispose d’une grille de lecture structurée qui va au-delà des observations empiriques habituelles. Le passage d’un modèle mental « un algorithme, un flux » à « 20 clusters avec des logiques distinctes » permet d’expliquer des phénomènes qui restaient mystérieux : pourquoi un média peut voir son trafic Discover chuter sur un segment sans que l’ensemble de son site soit affecté, pourquoi deux articles similaires peuvent avoir des trajectoires radicalement différentes, ou pourquoi les variations de trafic Discover semblent parfois aléatoires.
Cela dit, il faut garder les pieds sur terre. Ces données décrivent ce que le code client et les observations de panel révèlent à un instant donné. Elles ne donnent pas accès aux algorithmes de ranking côté serveur, aux pondérations des signaux, ni aux décisions en temps réel du système de personnalisation. Et comme le rappelle Yesilyurt lui-même : Google peut changer n’importe lequel de ces systèmes côté serveur, à tout moment, sans la moindre mise à jour de l’application.
Bibliographie
- Google Discover Architecture: Clusters, Classifiers, OG Tags, NAIADES — Metehan Yesilyurt, février 2026
- Pipelines Discover FR — 1492.vision
- Pipelines Discover EN — 1492.vision
- Comparaison pipelines FR/EN — 1492.vision
- Souriez, vous êtes embeddés ! (user embeddings) — 1492.vision
- Explorateur interactif des clusters Discover — 1492.vision
- 1492.vision : une étude sur 42 millions de cartes affirme que Google Discover repose sur plus de 20 pipelines internes — MeNow.fr