

Si vous avez déjà essayé d’optimiser les performances web d’un site web comportant un grand nombre de pages, vous avez dû remarquer que parmi les pages les plus lentes, on trouve souvent les pages paginées…
Par page paginée, j’entends ici des pages qui découpent une liste d’items en plusieurs pages différentes.
Pourquoi les pages paginées sont lentes ?
La lenteur de ces pages s’explique essentiellement pour deux raisons :
- elles ne sont que rarement mises en cache : soit parce qu’elles ne sont pas demandées assez souvent par les internautes, soit parce que leur contenu change souvent
- et pour générer une page paginée, on effectue en général des requêtes à base « d’offset ».
Le problème, c’est que l’utilisation d’un offset dans une requête sur une base de données n’est pas compatible avec des bonnes performances, surtout quand la pagination s’étale sur un très grand nombre de résultats.
Pourquoi les requêtes avec « offset » sont lentes ?
Pour afficher les résultats d’une page de la pagination, on interroge la base de données de la façon suivante :
- on envoie une requête à la base de données pour extraire une liste d’items dans un certain ordre
- on indique que l’on veut que les résultats commencent à une certaine ligne (la numéro 50 par exemple) : c’est la valeur de l’offset (le « décalage en français »)
- et on indique le nombre de résultats qui doivent s’afficher
Ce qui donne en langage SQL
SELECT * FROM table
ORDER BY timestamp
OFFSET 50
LIMIT 10Tout le monde fait comme cela depuis des dizaines d’années !
Sauf que cette méthode à un gros défaut, qui plombe les performances sur de grosses bases de données : pour afficher les lignes à partir de la position 50, le système va parcourir toutes les lignes AVANT la position 50. C’est vrai aussi si vous devez atteindre la position 5 milliards !
Donc l’inconvénient de la méthode offset, c’est que plus votre pagination est profonde, plus le temps de réponse sera long. Jusqu’à atteindre des temps de rendition rédhibitoires.
Cette méthode à un autre gros défaut que je cite au passage : si vous affichez la page 2, et qu’ensuite vous allez sur la page 3, et que la liste a changé parce qu’un item a été supprimé ou a été ajouté au même moment, vous risquez :
- soit de voir le dernier item de la page 2 reproduit en tête de la page 3
- soit de ne pas voir l’item qui était en tête de la page 3
La probabilité que ces événements arrivent est souvent faible, mais pas nulle. Cela fait des années que la méthode offset est considérée comme un compromis acceptable par la plupart des développeurs.
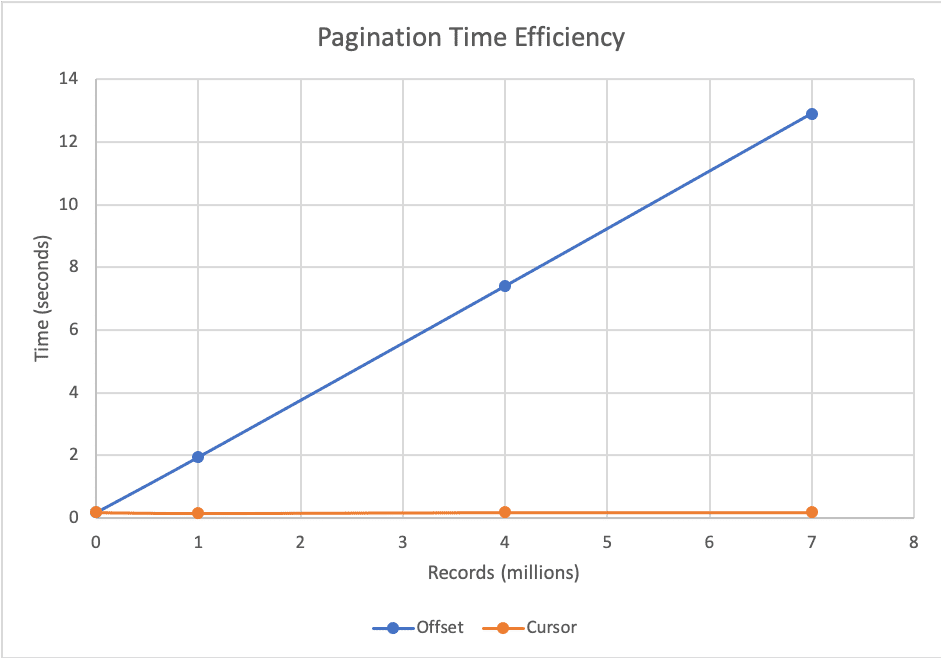
Source: https://laptrinhx.com/
Une alternative intéressante : la méthode à base de curseur
Il existe une méthode alternative, qui a été popularisée par les développeurs de Facebook. Elle montre sa supériorité surtout dans deux contextes :
- quand on utilise des ordre de tris simples, notamment sur le timestamp (liste ordonnée dans l’ordre de récence du contenu par exemple, ce qui est un cas courant sur les pages webs, par exemple sur un blog)
- et quand on veut utiliser des paginations de type long scrolling page (pages à défilement progressif) : dans ce contexte, les problèmes de résultats sautés ou en double deviennent perturbants, l’utilisateur s’en rend compte beaucoup plus facilement.
On trouve des paginations à base de curseur dans les api de Twitter par exemple, ou dans Shopify.
Comment fonctionne la pagination à base de curseur ?
La pagination basée sur le curseur fonctionne en spécifiant un pointeur correspondant à un élément unique de la table de données. Lors des requêtes suivantes, le serveur renvoie les résultats figurant après l’enregistrement défini par le pointeur. Cette méthode permet de remédier aux inconvénients de la pagination à base d’offset, mais au prix de certains compromis :
- Le curseur doit être basé sur une ou plusieurs colonnes uniques et séquentielles de la table source.
- On ne peut pas connaître le nombre total de pages ou le nombre total de résultats du jeu de données
- On ne peut pas sauter à une page spécifique => par contre on peut faire défiler les pages les unes après les autres (d’où l’utilisation de cette approche pour les long scrolling pages).
- Le browser doit communiquer avec le serveur pour obtenir la valeur du curseur pour la page suivante. Cela privilégie les implémentations exploitant des API et des interfaces en javascript.
Une requête SQL sur ce principe ressemblera à ça (un exemple pour l’API de Sopify) :
SELECT *
FROM `products`
WHERE `products`.`id` > 67890
ORDER BY `products`.`id` ASC
LIMIT 100Ici, le début de la page n’est pas défini par un offset (un « décalage ») mais par une clause where. Cela évite de parcourir toutes les lignes de la table avant le premier item correspondant au curseur (Ici, le curseur se base sur les identifiants produits). Pour fonctionner, une pagination à base de curseur renverra l’identifiant du dernier item +1 de la page (classiquement dans un mini fichier json) pour que le navigateur web puisse appeler la page suivante, ou le jeu de données suivants.
La pagination à base de curseur améliore les perfs, mais qu’en est-il du SEO ?
Cette technique est intéressante à envisager quand on est confronté à trois problèmes en SEO :
- les pages paginées sont très lentes, et cela nuit à l’UX et aux Core Web Vitals
- les pages sont tellement lentes que leur temps de rendition est supérieur au time out côté Googlebot : résultat, Google n’indexe que partiellement le contenu de ces pages
- les pages paginées sollicitent tellement les serveurs pour les fabriquer que les développeurs ont bloqué leur crawl dans le robots.txt. Evidemment, ce n’est pas forcément idéal pour faire découvrir toutes les pages d’un site, surtout si les urls de certaines pages ne se trouvent que dans les pages paginées profondes. Cela peut-être intéressant de tester cette solution pour voir si cette fois ci, on peut laisser les pages paginées être crawlées et indexées
Notez que les paginations traditionnelles (à base d’offset) créent moins de profondeur qu’une pagination à base de curseur. Ce phénomène de profondeur peut lui aussi conduire à des problèmes de crawl et d’indexation, plus sérieux qu’avec une méthode offset. Si vous basculez sur une pagination « curseur », pensez derrière à tester si les pages les plus éloignées de la première page (ou du début de la liste) sont bien indexées.
Mais dans tous les cas, il est recommandé d’éviter d’avoir besoin des pages paginées pour faire découvrir du contenu aux bots des moteurs. Il vaut mieux ajouter des pages de liens supplémentaires dans l’arborescence pour faire découvrir des pages profondes. Dans ce cas, cette faiblesse des paginations « curseur » n’aura pas de conséquences. Par contre, les pages présentant les premier jeux de données seront plus rapides à s’afficher, et auront plus de chances d’être correctement crawlées et indexées.
Conclusion
La pagination à base de curseur est une alternative plus performante intéressante à connaître. Pour des long scrolling pages, ou des sites faisant appel à des APIs et des interfaces en JS, ou des jeux de données qui bougent beaucoup et rapidement, c’est même une solution à considérer sérieusement.
Et même si au premier abord, cela peut sembler une mauvaise idée pour le SEO « en soi », si votre arborescence est optimisée, vous pouvez l’implémenter en vous disant que cela peut rendre le contenu de votre site plus facile à découvrir, crawler et indexer.