

Sujet relativement technique, l’analyse des logs permet de comprendre comment Google perçoit et crawl votre site. Au contraire d’autres crawler comme le célèbre Screaming Frog qui ne fait qu’imiter Googlebot, l’analyse des logs serveurs permet de savoir exactement quel est le cheminement de Googlebot sur les pages de votre site Web.
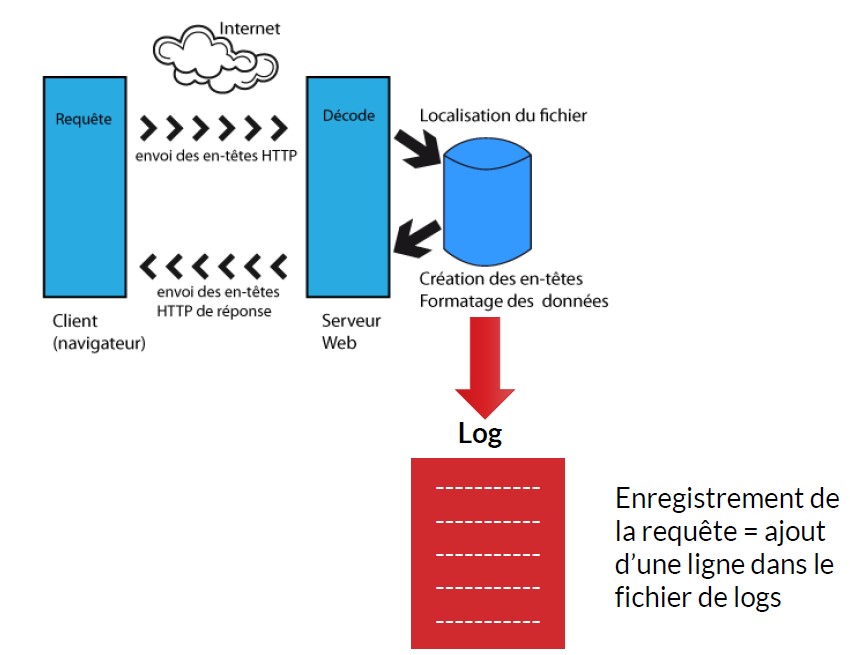
Les logs serveurs qu’est-ce que c’est ?
Ce sont des fichiers qui enregistrent tous les appels de ressources d’un site Web depuis un client distant. Cela inclue toutes les visites des internautes, mais également pour les robots des moteurs de recherche.

Un fichier de log, par exemple au format Apache par défaut, est une suite de lignes qui commencent par l’adresse IP de l’utilisateur qui s’est connecté, suivi par un timestamp qui identifie le moment où la requête a été faite, suivi par le type de requête, le code réponse et enfin le nombre d’octets renvoyés.
Pour le SEO, nous avons besoin d’autres champs, comme le referrer, le query string, l’user agent et l’hôte.
Pour résumer, nous avons besoin de :
- L’adresse IP de la source
- L’identité du client (user agent)
- Le nom de l’utilisateur distant (si http auth)
- Le groupe date/heure/fuseau de la requête
- La requête HTTP
- Le code réponse renvoyé par le serveur
- La taille du bloc de données retourné par le serveur
En règle générale, les informations manquantes sont symbolisées par un tiret -.
Pour le SEO, on va retenir principalement les lignes de logs qui contiennent Google (ou un autre moteur de recherche) dans le Referrer ou Googlebot dans le champ du User Agent.
Exploiter les logs serveurs
Où trouver les fichiers de logs ?
Le mieux est de récupérer vos fichiers de logs auprès de votre hébergeur qui stockent systématiquement ces fichiers dès que vous avez un site Web hébergé. Normalement, ces fichiers sont téléchargeables depuis votre interface d’administration de votre hébergement ou de votre compte chez votre hébergeur.
Il est important de bien différencier les types de fichiers logs que votre hébergeur met à votre disposition. Les logs qui nous intéressent sont les Access Logs. Les autres types de logs ne sont pas exploitables pour le SEO.
Quels sont les principaux types de formats pour les fichiers de logs ?
Les formats les plus courants sont IIS de Microsoft. Le problème de ce format est qu’il n’est pas standardisé. Il est donc important de s’assurer que vous avez accès à tous les champs nécessaires pour une bonne exploitation SEO des logs Microsoft.
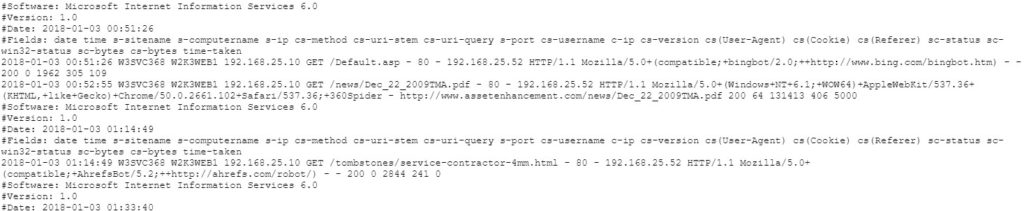
Vous avez également les logs issus d’un serveur Apache (NCSA). Le format standardisé Apache permet d’avoir tous les champs nécessaires. Il vous faut simplement vérifier que les logs sont au format Combined pour avoir l’User Agent et le Referrer. Le champ Host permet de séparer les domaines en cas d’hébergement multi domaines sur le même serveur.
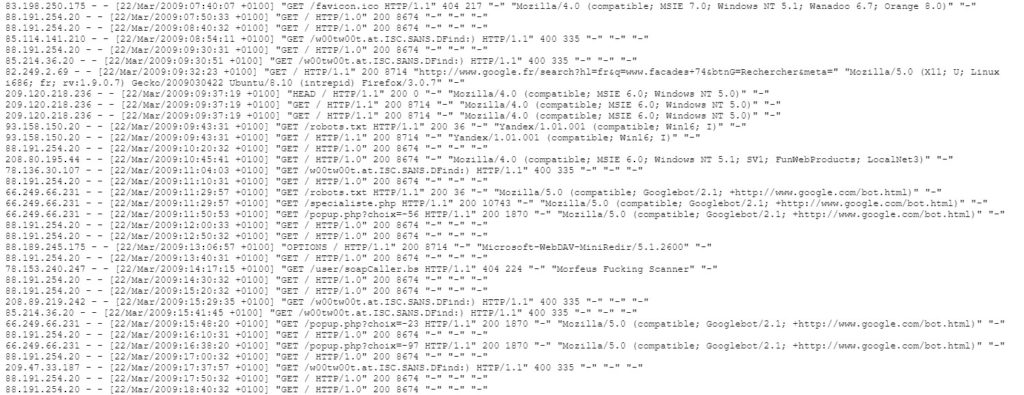
Pour en savoir plus : formats de logs
Vérifier les logs avant de s’en servir
Si vous avez un CDN qui répond aux requêtes à la place du serveur d’hébergement, totalement ou en partie, il faut également recueillir les logs du CDN. De même, si votre site utilise un Reverse Proxy, les HITS enregistrés sur le reverse proxy devront être récupérés.
Pour vous faciliter la tâche, vous pouvez paramétrer votre CDN et votre Reverse Proxy pour être transparents le temps pour vous de recueillir les logs nécessaires (à faire sur 2 ou 3 semaines minimum).
Il en va de même en cas de plusieurs serveurs frontaux qui répondent aux requêtes sur votre site Web. Dans ce cas, il faudra concaténer l’ensemble des fichiers Access Logs en faisant bien attention aux différents fuseaux horaires.
Dans un second temps, vérifiez le format des logs et que tous les champs nécessaires soient bien enregistrés. Certains fichiers de logs sont filtrables avant de les importer. Dans ce cas, il ne faut retenir que les lignes qui contiennent les éléments intéressants pour le SEO.
L’importance de la catégorisation
Il est indispensable de faire des catégorisations pour une exploitation utile des logs. Il faut identifier les différents templates de pages à l’aide de pattern d’URL par exemple, (pages produits, listing de produits, sous-catégories, catégories, vitrine, univers, etc.).
La catégorisation permettra de sortir des tableaux de données qui sont faits par catégorie de page.
Pour faire cette catégorisation, il est possible d’utiliser le PATH de l’URL si la structure du site est clair, sinon, dans la majorité des cas, il faut utiliser des outils plus puissants comme les Regex.
Quels outils utiliser pour manipuler les logs ?
Sous Linux, il existe des outils extrêmement efficaces comme Grep et eGrep, qui sont des outils gratuits. Sous Windows, vous pouvez utiliser PowerGrep (payant) qui permet de faire les mêmes manipulations. En version gratuite, il existe Grepwin qui est un peu moins puissant, et qui rend déjà bien service.
La manipulation des logs nécessite dans tous les cas de connaitre les Regex.
Il existe un autre outil, chez Microsoft, gratuit et puissant : Log Parser Studio.
Log Parser Studio permet d’extraire des informations relativement facilement en utilisant un langage de type SQL.
Voici, par exemple, la requête qui permet d’extraire les 500 premières lignes d’un fichier de logs type NCSA où le Referrer est Google.
SELECT distinct cs(User-Agent), count(*) as hits FROM '[LOGFILEPATH]' GROUP BY cs(user-agent) ORDER BY hits DESCSi votre hébergement contient les extensions ELK ou si vous souhaitez une alternative à Log Parser Studio, vous pouvez utiliser ELK (Elastic search Logstash Kibana). Plus d’infos sur ELK.
Parmi les solutions payantes les plus couramment utilisées, on trouve Splunk qui permet d’obtenir directement des rapports SEO à partir de vos fichiers de logs.
Analyse des logs
Maintenant que vous avez extrait les données de vos logs, voici les différentes analyses que vous pouvez effectuer.
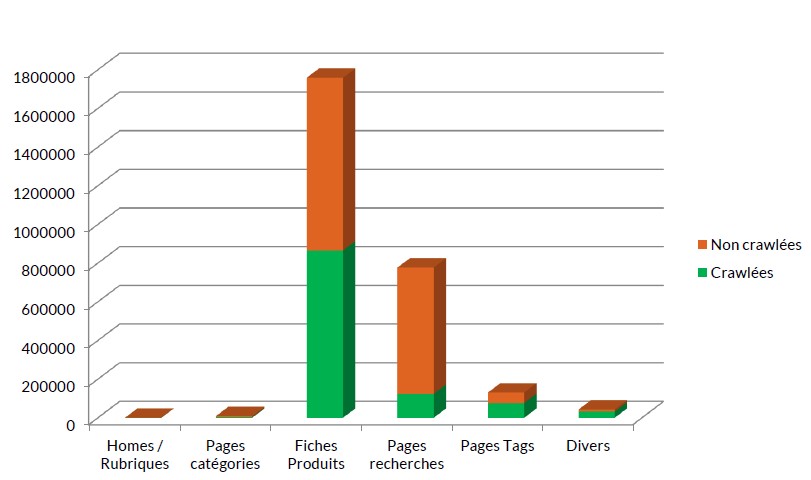
Connaître les pages crawlées
Basic, mais indispensable, cette analyse permet de savoir quelles pages de votre site sont réellement oubliées par Googlebot (et pas simplement celles que vous imaginez être non crawlées) pour différentes raisons comme problème technique, pagerank faible, doublon, page vide, etc.
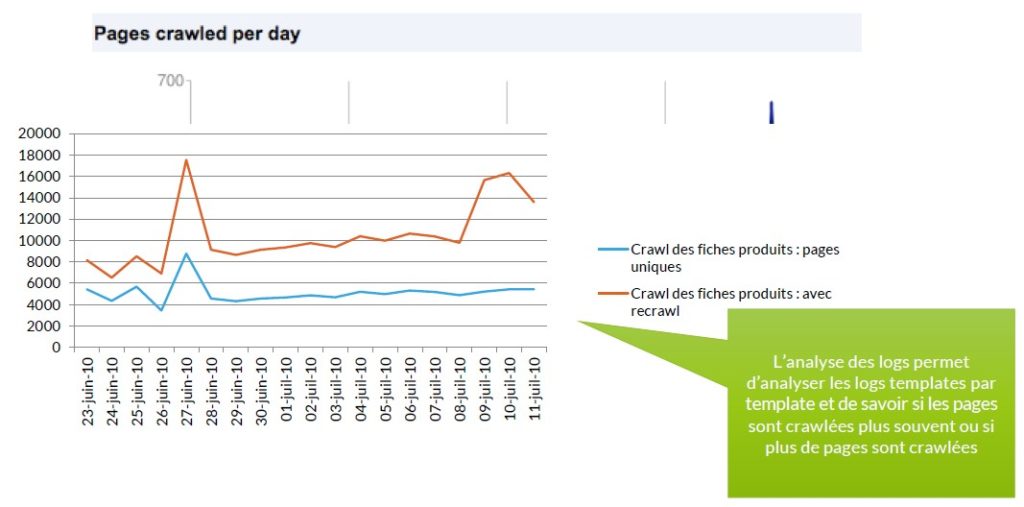
Connaître la fréquence de crawl
L’information est double : quel est le nombre de pages que Google crawl à chaque passage (crawl unique) ? Combien de temps faut-il à Google pour crawler entièrement mon site ? Quelle peut-être l’explication au recrawl fréquent de certaines pages et pas d’autres ?
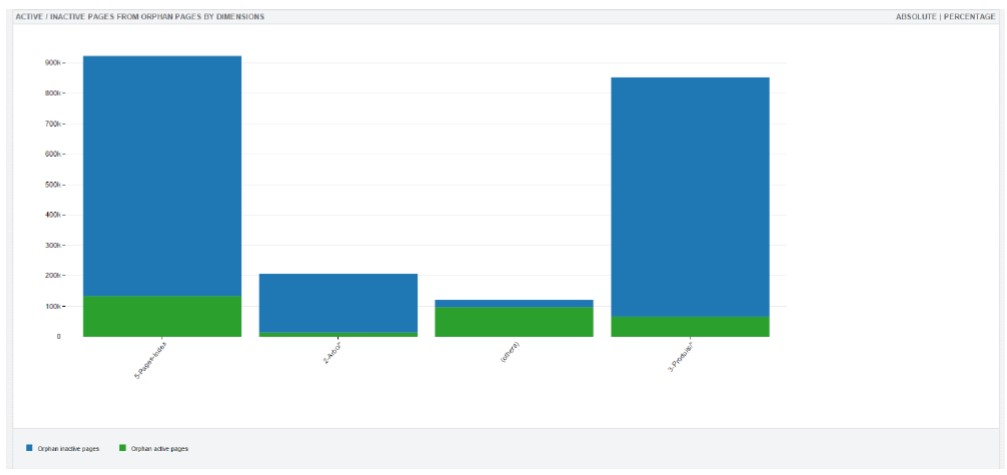
Quelles sont les catégories de page qui reçoivent le plus de trafic organique ?
Les pages qui ne reçoivent pas de visites en provenance d’un moteur de recherche au cours d’un mois donné sont, soit non indexées, soit très mal classées. Il est important de vérifier l’évolution du ratio pages visitées / pages ignorées.
Identifier les problèmes techniques
Monitorer les codes erreurs 3xx, 4xx, 5xx
Monitorer les performances coté serveur
Permet de détecter les problèmes de performance coté serveur et d’y remédier.
Il est très intéressant de combiner l’analyse des logs avec un crawl de Screaming Frog, par exemple, pour croiser les informations pour en tirer des informations très intéressantes pour le SEO. C’est ce qu’on appelle l’overlap analysis et qui fera l’objet d’un prochain article.