

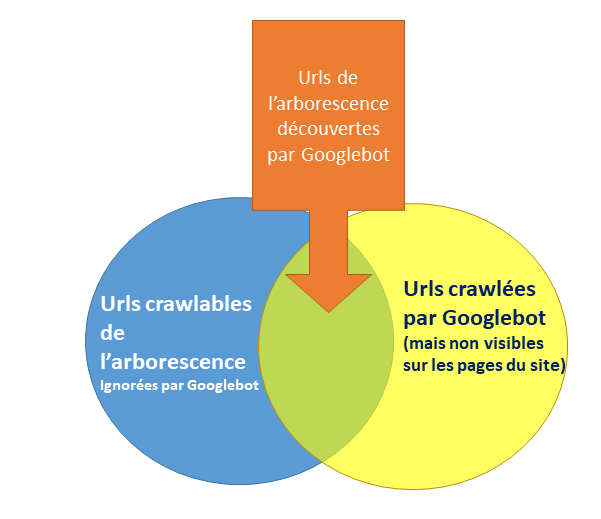
Lorsque l’on analyse les urls découvertes par un crawler et qu’on les compare à la liste des urls crawlées par Google, on découvre le plus souvent que certaines d’entre elles n’ont pas été visitées par Googlebot.
Le contenu de ces urls est donc inconnu pour Google, et elles ne sont pas indexées.
Le fait qu’une partie des urls d’un site ne soient pas indexées a évidemment un impact négatif sur le trafic SEO capté.
Par contre, la croyance selon laquelle le phénomène de « non indexation » des urls est récent, et/ou de plus en plus fréquent est totalement erronée. Il se passe sur ce sujet la même chose pour les pages non indexées que pour les astéroïdes géocroiseurs : avant d’avoir les bons télescopes et avant qu’on les cherche systématiquement, ils étaient déjà là mais personne ne le savait. On détecte plus facilement les pages non indexées avec les outils SEO modernes, mais cette situation a toujours existé.
Nous allons faire le point sur les causes habituelles de cette situation et comment y remédier.
Premier cas simple : Google crawle en fait une variante de l’url
Avant d’analyser les pages « ignorées » par Googlebot, il est important de terminer les analyses effectuées lors du traitement des pages orphelines que nous avions décrites dans cet article :
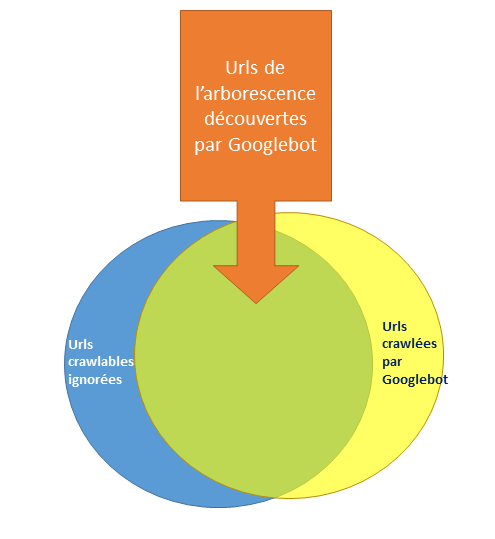
En effet, le cas le plus fréquent que l’on rencontre ce sont les urls crawlées faussement orphelines, c’est à dire que la version crawlée et/ou indexée est une variante crawlée préférentiellement par Googlebot.
Ces cas se traitent en même temps que les pages faussement orphelines qui leurs sont associées, et en général, la liste des pages de l’arborescence réellement oubliées par Googlebot est beaucoup plus réduite après ce traitement.
Faut-il corriger ces problèmes systématiquement ?
L’impact de la correction de ces pages « faussement » ignorées est assez variable. Cela dépend du degré de confusion que cela engendre chez Google.
- si Google canonicalise tout seul la variante d’url et la page du site, corriger la situation n’aura un impact que sur le budget de crawl, et encore, pas toujours
- Par contre, si Google canonicalise les deux urls dans le mauvais sens, crawle les deux versions et parfois indexe la variante, la situation peut avoir un impact direct sur le trafic SEO généré et les positions occupées.
- En plus, il y’a aussi un réel impact indirect : les analyses du crawler et de l’indexeur de Google sur la qualité de certaines sections de votre site peuvent être faussées par la situation. En clair il peut penser qu’une section de votre site est remplie de pages doublons et cesser de la crawler à cause de cela
Donc oui, il est préférable d’essayer d’améliorer la situation et de veiller à ce que les urls crawlées et indexées soient autant que possible les mêmes que celles que vous montrez sur votre site.
En pratique, vous ne parviendrez jamais à une situation parfaite.
Mais faciliter la découverte des urls de votre site est toujours une bonne idée.
Et quand on part d’une situation ou une minorité d’urls figurant vraiment dans l’arborescence du site est crawlée, et qu’on inverse les proportions, il n’est pas rare de voir une réelle amélioration sur plusieurs KPI comme :
- des gains de position
- plus de trafic capté
- plus d’urls uniques crawlées par jour
- etc.
Deuxième cas : Google ignore une url qui figure dans l’arborescence du site
Une fois isolés les cas où Google ne crawle pas une url de l’arborescence mais sa variante, on tombe sur des cas où l’url est vraiment ignorée par Google.
Dans ce cas, il faut essayer de regrouper les cas par patterns d’urls, et les traiter par niveau décroissant de volumétrie. En clair, on traite d’abord les cas qui font perdre le plus de potentiel, et si on a le temps et les ressources pour, on traitera ensuite les cas rares, voire les cas limités à une seule url.
Ensuite on essaie d’établir un diagnostic en se posant les questions suivantes
1. L’url est-elle découvrable par un crawler comme Googlebot ?
En théorie, ce cas ne devrait pas exister : après tout, vous avez découvert des urls ignorées en comparant la liste des urls crawlables données par votre crawler SEO préféré, et ensuite vous l’avez comparée avec la liste des urls crawlées par Googlebot d’après les logs serveurs.
C’est le moment de vérifier la configuration de votre crawler : était-il vraiment configuré comme Googlebot ? Respecte-t’il le robots.txt, le nofollow etc.. ?
Il y’a aussi des cas où le serveur aura un comportement différent s’il est confronté à une vraie visite de Googlebot vs un bot qui se fera passer pour Googlebot !
Pour lever le doute, cela vaut le coup de tester l’url ignorée dans la Google Search Console :
- si vous voyez que Googlebot ne peut y accéder, vous avez identifié un cas intéressant d’url accessible pour votre crawler mais pas pour Googlebot. Ces cas existent, ont des causes multiples qu’il serait fastidieux de lister ici, mais en général on finit par en identifier la raison avec un peu de perspicacité
- si Googlebot peut y accéder, alors il faut s’intéresser à ce qui se passe sur les pages de votre site qui montrent l’url à découvrir.
Dans la pratique, il faut analyser le code des pages qui contiennent un lien vers la page ignorée, et vérifier que Googlebot peut découvrir l’url.
On voit de plus en plus ce cas là par exemple :
- l’url est générée en CSR dans le navigateur, mais ce contenu demande trop de temps pour être généré et être parsé par Googlebot (par contre cela passe crême dans Screaming Frog)
2. L’url est-elle réellement crawlable ?
Il y’a quelques années, quand Google avait encore une interprétation très personnelle des directives dans un robots.txt, il n’était pas rare de voir des schémas d’urls crawlables d’après Screaming Frog, Oncrawl ou Botify être considérés comme non crawlables par Google.
Aujourd’hui, tout le monde utilise des règles standard pour interpréter un robots.txt, et la seule chose à vérifier c’est la configuration de votre crawler :
- tester les urls à problème dans l’outil ad hoc de la search console https://www.google.com/webmasters/tools/robots-testing-tool
- si l’outil vous dit que l’url n’est pas crawlable, alors que votre crawler préféré dit le contraire, corrigez la config, reprenez le crawl et recommencez vos analyses
3. Vos pages sont elles trop lentes ?
Si votre crawler arrive à crawler vos urls, mais pas Googlebot, cela peut s’expliquer par la lenteur de téléchargement des urls.
Vérifiez dans le rapport sur les temps de téléchargement des pages HTML dans la Google Search Console le temps moyen : au dessus de 500 ms de temps moyen, il est possible qu’une partie de vos urls mettent plus d’une seconde à être téléchargée.
A partir de cette limite empirique, Googlebot change de comportement de crawl :
- il crawle les urls lentes moins souvent
- et dans les cas extrêmes, il cesse de crawler les patterns d’urls trop lents !
L’url est crawlable, mais Google ne veut pas la crawler
Le plus souvent, Google ignore des urls, non pas parce qu’il ne peut pas les découvrir ou les crawler, mais parce qu’IL NE VEUT PAS LES CRAWLER.
Derrière Googlebot, il existe un logiciel qui est spécialement chargé de gérer la file d’attente des urls à crawler, en définissant l’ordre de crawl et de recrawl de chaque url. Ce logiciel s’appelle l’ordonnanceur.
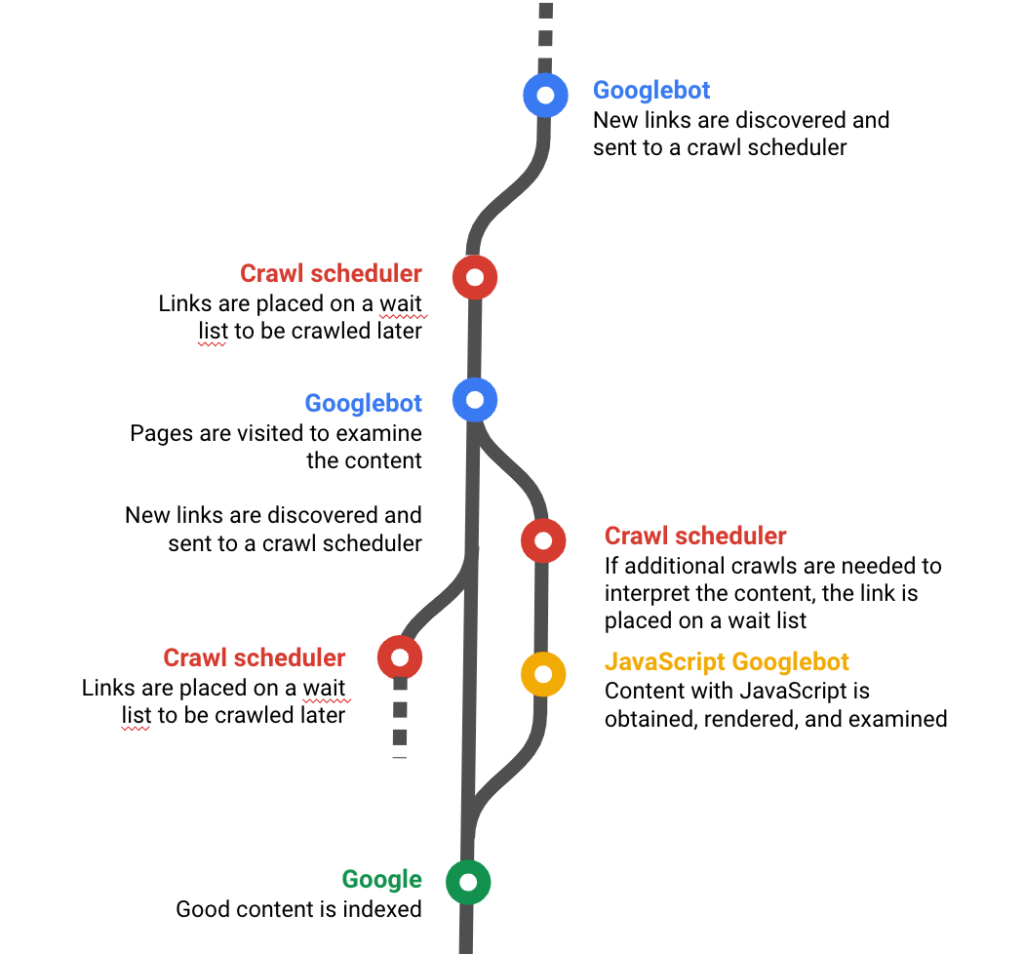
Source : Oncrawl : https://fr.oncrawl.com/seo-technique/site-web-crawlable/
L’ordonnanceur se base sur un « score d’intérêt » de la page pour l’index de Google, qui lui permet de déterminer :
- si une url doit être crawlée en priorité, parce qu’elle est indispensable comme réponse à des requêtes des internautes
- ou si au contraire, il s’agit d’une url qui peut être ignorée
Sur quels critères se base Google pour définir les urls à crawler ou à ignorer ?
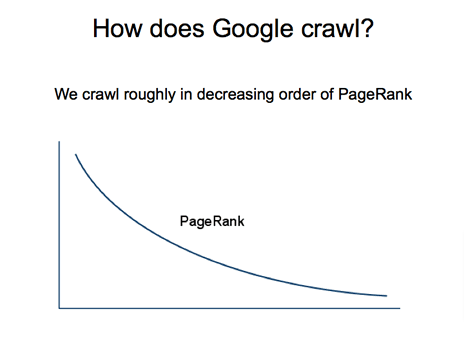
Le critère le plus important sont les scores d’importance de la page. Donc si une url est ignorée, c’est souvent :
- parce qu’elle a un score de pagerank très faible
- et/ou qu’elle est située dans les profondeurs de l’arborescence
Notez que ces deux critères sont intimement corrélés.
Ensuite, Google cherche à maintenir son index à jour. Donc s’ils détectent qu’une nouvelle page risque de contenir une réponse à une question d’actualité, ou un nouveau produit mis en vente récemment, alors ces pages seront crawlées en priorité, et les pages qui contiennent habituellement ces listes d’urls nouvelles seront également recrawlées plus souvent et en priorité.
Enfin Google cherche des réponses de qualité à placer dans son index.
Si les urls montrent :
- des problèmes techniques
- des problèmes de qualité : pas de contenu ou presque
- de doublons ou de quasi doublons
- etc.
Alors, Googlebot risque de ne pas crawler ces pages. Et même s’il les crawle, il est fréquent que Googlebot ne les indexe pas.
Un crawl « prédictif » à base d’IA
Ce comportement de crawl à base de scores est apparu au plus tard en 2009 chez Google. Il existait un système moins sophistiqué avant, qui fonctionnait « a posteriori » : une fois les urls crawlées et analysées, Google évaluait l’intérêt de les recrawler.
Aujourd’hui, le système fonctionne a priori : les scores d’intérêt des urls pour l’index permettent de calculer une probabilité qu’une url sera intéressante pour l’index, avant même de l’avoir crawlée une première fois !
Ces scores s’analysent par « bucket » d’urls. Dans la bouche de Google, le terme « bucket » ici signifie un groupe d’urls qui partagent visiblement un grand nombre de caractéristiques, comme une rubrique d’articles dans un site éditorial ou l’ensemble des pages marques sur un site marchand.
La notion de bucket s’appuie aussi sur les patterns d’urls et le path : c’est l’une des raisons pour laquelle les structures d’urls à plat (sans répertoire virtuel) et totalement réécrites sont déconseillées car elles gênent la détection de ces fameux « buckets ».
Depuis quelques mois, Google a annoncé avoir intégré de l’IA dans l’ordonnanceur pour mieux prédire les pages intéressantes pour son index.
Conclusion : pour faire indexer les pages ignorées par Google, il faut améliorer leurs scores d’intérêt
Les causes qui expliquent le fait que certaines des urls crawlables de votre site ne sont pas crawlées sont donc parfois techniques. Il suffit de corriger le problème pour que Googlebot puisse enfin les découvrir et/ou les crawler.
Mais le plus souvent, les pages souffrent d’un déficit de score d’intérêt. Dans ce cas, ce qu’il faut faire c’est améliorer ces scores :
- en optimisant l’arborescence du site (en diminuant la profondeur)
- en maximisant le pagerank interne de ces pages
- en évitant les problèmes de qualité sur le site : présence massive de pages vides, de DUST, de contenus dupliqués, de contenus
- et en améliorant la qualité perçue par Google des buckets d’urls visiblement ignorés
Dans un prochain article, nous verrons pourquoi Google refuse d’indexer certaines pages, même après les avoir crawlées :
- Pourquoi les sitemaps XML ne sont pas l’arme ultime pour faire indexer vos contenus
- Pourquoi certaines stratégies proposées ici ou là sont obsolètes (le bot herding, le pagerank sculpting)
- Pourquoi le budget de crawl est une notion parfaitement inutile dans la pratique
- Pourquoi soumettre les urls à la main ou via des outils ne marche pas à tous les coups
- Les outils du marché pour tester l’indexation sont ils efficaces et utiles ?
- Et comment réussir à faire indexer un maximum de vos urls dans différents cas de figure
Merci pour cet article.
Je prends volontiers le lien de la source de la présentation de Matt Cutts sur le fait que la vélocité du recrawl dépend pour partie du PageRank.
Ou s’il y a une source plus récente, de John MuMu par exemple, qui dit la même chose 🙂
Merci
Bonjour,
A propos des informations données par Matt Cutts :
https://youtu.be/rdPnRn_qQHw
C’était également indiqué dans un deck Powerpoint qui n’est plus en ligne, mais que j’ai du conserver.
Sinon, pas plus officiel que cette page :
https://developers.google.com/search/blog/2017/01/what-crawl-budget-means-for-googlebot
et cette phrase :
« Popularity: URLs that are more popular on the Internet tend to be crawled more often to keep them fresher in our index. »