

Il y’a une dizaine d’années, une des méthodes les plus répandues pour vérifier qu’un visiteur qui prétendait être Googlebot était bien un bot de la firme de Mountain View consistait à se fier à des plages d’IP plus ou moins officielles correspondant à Google.
Le problème avec cette méthode, c’est qu’elle n’était pas fiable à 100% : beaucoup de sites qui pratiquaient le cloaking l’ont appris à leurs dépens. Il suffisait qu’une IP manque à l’appel dans ces fichiers, et Google détectait que deux versions différentes étaient proposées pour le même site. Ballot !
Beaucoup se sont vu infliger des pénalités par manque de fiabilité de cette méthode.
De la même façon, détecter les passages de Googlebot pour lui envoyer une version en cache ou prégénérée (une pratique conforme aux Guidelines cette fois-ci) s’avérait aléatoire avec cette méthode.
Google préconisait donc ces derniers temps de ne pas se fier uniquement au User Agent (on comprend pourquoi) mais de vérifier que Googlebot était bien Googlebot en faisant une interrogation des « reverse DNS » avec la commande Host
La méthode des reverse DNS : fiable, mais lourde si vous devez vérifier beaucoup d’IP !
Google préconise cette méthode car elle est imparable. Si vous trouvez dans vos logs une IP qui a crawlé des pages de votre site avec un User Agent Googlebot, il suffit d’effectuer une requête de type « reverse DNS avec la commande host », et la réponse vous indiquera si la visite vient bien d’un serveur de Google.
> host 66.249.66.1
1.66.249.66.in-addr.arpa domain name pointer crawl-66-249-66-1.googlebot.com.
> host crawl-66-249-66-1.googlebot.com
crawl-66-249-66-1.googlebot.com has address 66.249.66.1La deuxième étape de la vérification consiste à faire une résolution DNS normale sur le host qui a été détecté à la première étape :
- si vous retombez sur la même IP : tout va bien
- si l’IP n’est pas la même : il y’a quelque chose qui cloche, et ce n’est pas Google finalement.
Autant il est facile de « spoofer » le user agent, autant il est difficile de simuler l’adresse crawl-xx-xx-xx-xx.googlebot.com.
Ok, le spoofing de host ça existe, mais faire cela pour éviter de se faire prendre en aspirant un site avec Zyte, c’est un peu excessif…
C’est donc très sûr comme méthode.
Ah, au passage, Google ne donne la méthode qu’avec la commande « host », qui est une commande Linux/Unix. Si vous voulez tester avec Windows, il faut tester avec la commande Nslookup en ligne de commande.
Tapez cmd dans la barre de recherche de windows.
Puis ceci :
C:\Users\xxxx>nslookup 66.249.66.1
Serveur : xxxxxxxx
Address: 192.168.1.1
Nom : crawl-66-249-66-1.googlebot.com
Address: 66.249.66.1
Mais en même temps, ça prend du temps de faire une résolution inverse, puis une résolution DNS directe, et cela demande de savoir programmer pour automatiser la vérification. Bref si vous voulez vérifier les IP contenues dans un fichier de logs, cela demande un savoir faire technique certain.
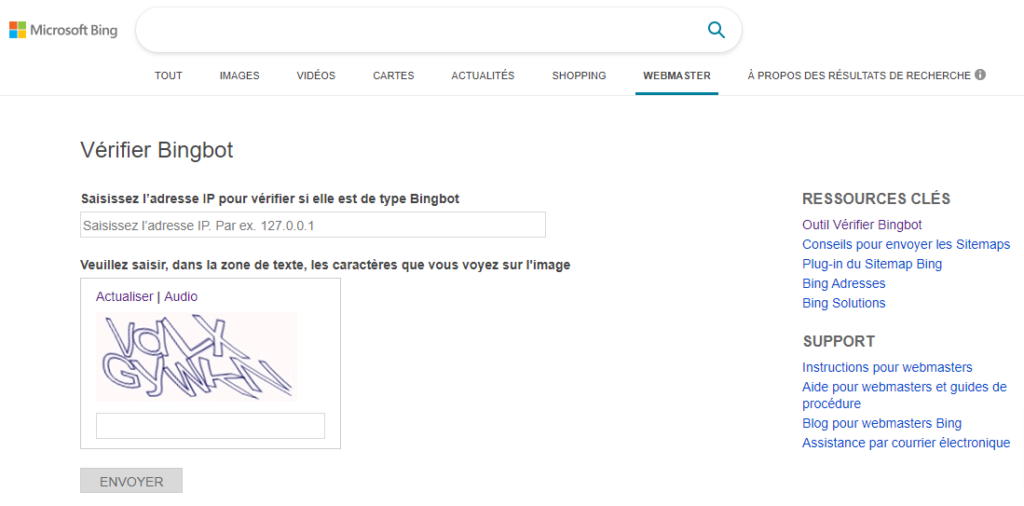
Notons que Bing propose une méthode très pratique pour vérifier qui est vraiment derrière les visites de Bingbot.
Il suffit d’entrer les IP correspondantes sur cette page :
https://www.bing.com/toolbox/verify-bingbot
Update du 15 novembre 2021 : les équipes de Bing ont décidé de communiquer elles-aussi les plages d’IP utilisées par Bingbot :
https://www.bing.com/toolbox/bingbot.json
Google communique dorénavant sur ses plages d’IP officielles
Mais voila que Google a annoncé qu’ils publieraient dorénavant deux listes d’IP officielles pour leurs crawlers, qui apparaissent sur la page de support sur la vérification de Googlebot:
https://developers.google.com/search/docs/advanced/crawling/verifying-googlebot
- la première correspond aux IP de Googlebot : https://developers.google.com/search/apis/ipranges/googlebot.json
- la seconde à tous les autres crawlers de Google :
https://www.gstatic.com/ipranges/goog.json

Les listes sont fournies au format json, ce qui rend leur réutilisation par des programmes relativement facile.
Qu’est-ce que cela change ?
Cette nouvelle méthode donne un moyen simple et efficace pour détecter la visite de « faux » Googlebot. Il suffit de crawler le web pour voir que ces dernières années beaucoup de sites ont mis en place des outils pour éviter que leur contenu soit aspiré par les robots des concurrents. D’autres mettent cela en place pour éviter que des petits malins utilisent la porte dérobée ouverte sur un paywall pour les bots des moteurs en se faisant passer pour eux. Mais ces outils sont parfois chers et difficiles à employer.

Il devient plus facile d’écrire des scripts de détection de « bad bots » beaucoup plus rapides que des reverse DNS systématiques…
Chouette, on va pouvoir à nouveau faire du cloaking ? Non
Si Google ne communiquait pas sur ses listes d’IP officiellement avant, c’était probablement pour lutter contre le cloaking. En effet, si vous êtes capable de détecter avec certitude à chaque fois qu’un visiteur vient de Google, vous allez pouvoir toujours lui envoyer la version « spéciale Google ». Et ceci, même si le bot se fait passer pour un utilisateur normal avec un User Agent classique.
A l’occasion de ce changement, John Mueller a semblé dire que les problèmes de cloaking avaient plus ou moins disparu, et que c’était ce qui permettait à Google de révéler cette liste.
Nous ne l’avons pas encore testé, mais il y’a peu de chances que ces deux listes d’IP couvrent TOUS les outils et services de Google. C’est plus un moyen de whitelister les IP des crawlers de Google efficacement. Mais Google peut toujours faire des tests de présence de cloaking en utilisant d’autres plages d’IP.
Cela signifie que pour faire du cloaking, vous devez utiliser des plages d’IP beaucoup plus larges, et là, l’expérience prouve que les listes qui trainent sur le net sont d’une fiabilité douteuse.
Conclusion : rien ne change côté cloaking, et on dispose à présent de deux méthodes fiables pour identifier les bad bots parmi ceux qui utilisent le User Agent « Googlebot ».