

Parmi les trois promesses adressées le 29 juin aux éditeurs de presse français, une seule possède déjà une traduction technique visible. Le contrôle, c’est-à-dire la faculté de choisir d’apparaître ou non dans les fonctionnalités génératives, n’est pas une intention vague : c’est un réglage qui existe, qui tourne au Royaume-Uni depuis le 17 juin 2026, et que la France s’apprête à recevoir avec le déploiement estival des Aperçus IA (le contexte de cette annonce est détaillé dans notre article du 30 juin).
Ce réglage s’appelle le Search generative AI control (contrôle de l’IA générative dans Search). Il se loge dans Google Search Console, l’outil gratuit que Google met à disposition des propriétaires de sites pour suivre leur présence dans le moteur. Derrière une interface en apparence anodine, trois boutons radio, il concentre un arbitrage stratégique que beaucoup d’éditeurs vont devoir trancher dans les semaines qui viennent. Voici comment il fonctionne réellement, ce qu’il fait et ce qu’il ne fait pas, et pourquoi le calcul ne sera pas tout à fait le même à Paris qu’à Londres.
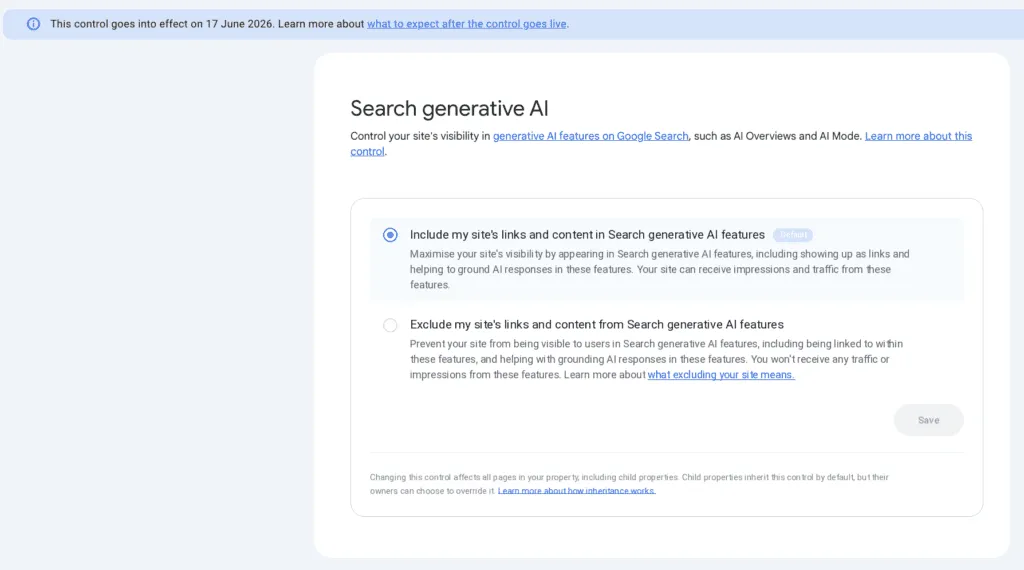
Un interrupteur, trois positions
Le contrôle se trouve dans Search Console, sous Paramètres, rubrique Search generative AI. Il gouverne la présence du site dans trois surfaces génératives : les AI Overviews (Aperçus IA), ces résumés rédigés par le modèle Gemini en tête des résultats, l’AI Mode (Mode IA), l’interface de recherche conversationnelle, et les fonctionnalités d’IA générative de Google Discover, le flux de recommandation des appareils mobiles.
Trois positions sont possibles, et une seule s’applique à la fois :
- Inclure les liens et le contenu du site dans les fonctionnalités génératives. C’est la valeur par défaut de toute propriété. Le site peut alors recevoir des impressions et du trafic depuis ces surfaces, et son contenu sert à étayer les réponses.
- Exclure les liens et le contenu. Le site cesse d’être visible dans ces fonctionnalités, n’y reçoit plus aucune impression ni aucun trafic, et son contenu ne peut plus servir à générer ou à ancrer une réponse.
- Hériter du parent, position que nous détaillons plus loin, et qui devient la valeur par défaut dès qu’une propriété en possède une autre au-dessus d’elle.
Le point à retenir : il n’existe pas de réglage intermédiaire. On ne peut pas demander à apparaître sans servir d’ancrage, ni doser sa présence. C’est inclure ou exclure, tout ou rien.
Source : https://pedromatias.co.uk/exclude-your-site-from-google-ai-overviews-in-the-uk-but-should-you/
Exclure ne veut pas dire disparaître de Google
C’est la confusion la plus fréquente, et la plus lourde de conséquences. Exclure son site des surfaces génératives ne le retire pas de la recherche. Google est explicite sur ce point : ce contrôle n’est pas utilisé comme signal de classement ni d’inclusion affectant les autres parties du moteur. Un site exclu continue donc d’apparaître normalement dans les liens organiques classiques et dans le flux Discover non génératif.
L’exclusion connaît d’ailleurs plusieurs limites précises, qu’il faut avoir en tête avant de modifier le paramétrage :
- elle ne s’applique qu’aux surfaces génératives listées plus haut, pas au reste du moteur,
- elle n’écrase pas les choix faits par ailleurs dans Merchant Center ou Google Ads,
- elle n’empêche pas le contenu de continuer à nourrir la compréhension globale du moteur, par exemple l’analyse de la langue des requêtes,
- elle ne concerne pas l’entraînement des modèles, qui relève d’un autre dispositif.
Ce dernier point mérite qu’on s’y arrête, car il alimente une seconde confusion, plus structurante encore.
Quatre commandes, quatre besoins différents
Un éditeur dispose désormais de quatre leviers pour piloter le rapport de son contenu à l’IA et au moteur. Les confondre conduit à des décisions contre-productives. Chacun répond à un besoin différent, et cela mérite d’être clarifié car les confusions et erreurs deviennent faciles à faire.
Google-Extended répond à la question de l’entraînement. C’est le contrôle d’exploration qui permet de refuser que le contenu serve à entraîner les modèles Gemini. Il est disponible en France depuis septembre 2023. Il ne bloque pas l’apparition dans les Aperçus IA : un site peut très bien refuser l’entraînement et continuer d’alimenter les réponses génératives via le processus de grounding.
Le nouveau Search generative AI control répond à la question de l’apparition dans les fonctionnalités IA de Google. Il décide si le contenu se montre et sert d’ancrage dans les surfaces génératives, sans toucher au classement organique.
Le nosnippet répond à la question de l’extrait. Cette directive empêche l’affichage d’un extrait textuel dans les résultats. Elle pouvait jusqu’ici écarter un contenu des Aperçus IA, mais au prix de l’extrait organique, donc d’une perte de visibilité dans les liens bleus eux-mêmes. Le nouveau contrôle a précisément pour intérêt de désolidariser ces deux effets : bloquer l’IA sans sacrifier l’extrait classique.
Le noindex répond à la question de l’indexation. Il retire purement et simplement une page de l’index, donc de toute la recherche. C’est l’option la plus radicale, sans rapport avec les nuances précédentes.
La hiérarchie des propriétés, seul réglage fin disponible
Puisque le contrôle est binaire, comment faire du sur-mesure quand un site mêle des contenus que l’on veut exposer et d’autres que l’on préfère protéger ? La réponse passe par l’arborescence des propriétés de Search Console, c’est-à-dire les différentes briques par lesquelles un même site peut être déclaré : domaine entier, sous-domaine, ou répertoire (préfixe d’URL).
Par défaut, une propriété hérite du réglage de son parent le plus proche ayant cessé d’hériter. Si aucun parent n’a configuré de valeur, elle suit celle du domaine de premier niveau. Le propriétaire d’une propriété enfant peut toutefois rompre cet héritage et imposer un réglage spécifique à cette propriété et à ses sous-pages.
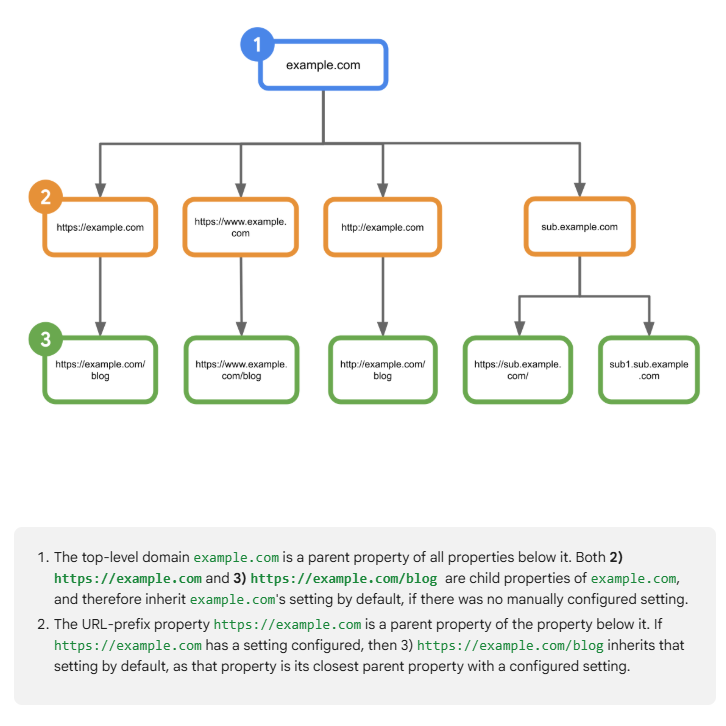
Concrètement, cela ouvre une marge de manoeuvre que le bouton seul n’offre pas. Un éditeur peut maintenir l’ensemble de son domaine dans les fonctionnalités génératives tout en excluant un sous-domaine ou un répertoire précis, par exemple une verticale premium, une base documentaire monétisée ou une rubrique d’archives. C’est la seule granularité réellement disponible, et elle suppose d’avoir correctement segmenté ses propriétés en amont. Les sites qui ne déclarent qu’un domaine global se priveront de fait de cette finesse.
Un rapport qui montre les impressions, pas les clics
Le contrôle ne vient pas seul. Google l’a livré avec un rapport de performance dédié aux surfaces génératives, séparé du rapport de performance habituel. Son rôle annoncé : aider à estimer l’effet d’un changement de réglage avant de l’appliquer.
Ce rapport fournit cinq dimensions : les impressions, c’est-à-dire la fréquence à laquelle des URL du site apparaissent dans les fonctionnalités génératives de Search et de Discover, les pages concernées, les pays, les appareils et les dates, avec une granularité horaire à mensuelle. Une absence saute aux yeux : il ne contient aucune donnée de clic.
Cette lacune n’a rien d’anecdotique. Sans clic, un éditeur voit qu’il apparaît dans une réponse IA, mais ignore combien d’internautes ont cliqué vers son site, et donc l’ampleur réelle de la cannibalisation de son trafic. Le rapport mesure la visibilité, pas la captation. À notre connaissance, Google n’a pas communiqué de calendrier pour l’ajout d’un indicateur de clic, en se bornant à évoquer l’introduction de métriques supplémentaires au fil du temps. L’outil censé éclairer la décision ne l’éclaire donc qu’à moitié.
Le calcul français ne sera pas le calcul britannique
Au Royaume-Uni, l’arbitrage est d’une simplicité brutale : du trafic potentiel contre une cannibalisation possible. Le dispositif y découle d’une obligation réglementaire, le Publisher Conduct Requirement imposé à Google par la CMA (Competition and Markets Authority, l’autorité britannique de la concurrence) le 3 juin 2026.
En France, une variable s’ajoute, et elle change tout. La rémunération au titre des droits voisins, ce mécanisme qui oblige depuis 2019 les plateformes à payer les éditeurs pour la réutilisation de leurs contenus, va se brancher sur les impressions générées par l’IA. Selon les engagements communiqués aux éditeurs, chaque citation d’un titre de presse dans un résumé, assortie d’un lien, comptera comme une impression, et c’est sur ce volume que reposera la rémunération.
La conséquence est paradoxale. Pour un éditeur de presse couvert par les droits voisins, exclure revient à renoncer simultanément au trafic IA et au revenu adossé aux impressions IA. L’opt-out coûte donc plus cher à Paris qu’à Londres. Pour tout le reste du web français, e-commerce, sites de services, éditeurs de niche, il n’existe en revanche aucune contrepartie au grounding : le choix se réduit à du trafic incertain ou au néant. La liberté que Google met en avant reste une liberté sous contrainte, sans position intermédiaire, sans mesure du clic, et compensée pour une seule catégorie d’acteurs.
Ce que les éditeurs français peuvent faire maintenant
Une précision s’impose : à ce jour, le réglage n’est pas accessible en France.
Il reste réservé à un sous-ensemble de propriétaires britanniques, et Google n’a pas communiqué de date d’extension. Le courrier du 29 juin promet bien un dispositif de contrôle avec le déploiement estival, mais le véhicule technique exact côté français n’est pas confirmé.
Il pourrait d’ailleurs exister deux portes de sortie distinctes. Le Search generative AI control concerne tout le web, sans distinction de statut. La rémunération droits voisins, elle, passe par une mise à jour des contrats des éditeurs de presse déjà sous accord. Un même éditeur de presse pourrait donc relever des deux logiques à la fois, là où un site marchand ne disposera que du bouton Search Console. Ce point reste à vérifier à mesure que Google précisera les modalités françaises.
Dans l’attente, trois gestes utiles. Vérifier la segmentation de ses propriétés dans Search Console, puisque c’est elle qui conditionnera toute granularité ultérieure. Clarifier en interne sa position de principe, surface par surface, plutôt que de la découvrir dans l’urgence du déploiement. Et surveiller l’apparition du rapport de performance IA, qui livrera les premières mesures de visibilité, à défaut de mesurer les clics.
Sources
- Search generative AI control (Google Search Console Help)
- Introducing Search Generative AI performance reports in Search Console (Google Search Central Blog)
- Google-Extended (Google Search Central, documentation des crawlers)
- Block search indexing with noindex (Google Search Central)
- Google Search Generative AI Control Explained (Search Engine Roundtable, Barry Schwartz)
- Google Search Console AI performance reports and controls to block your content in AI responses (Search Engine Land, Barry Schwartz)
- Google search publisher conduct requirement (GOV.UK, CMA)
- AI Overviews et AI Mode en France : après des mois de spéculation, c’est officiel (Neper)
- Définition de « grounding » (ancrage) (Neper)