

En 2019, lors de la conférence « Better Together » organisée par Ryte, Martin Splitt, Developer Advocate au sein de l’équipe Google Search Relations, raconte un cas qui fait froid dans le dos. Un site web complet, avec des dizaines de pages de contenu, n’apparaît tout simplement pas dans les résultats de Google. Seule la page d’accueil est indexée. Le reste ? Invisible. Pourtant, quand on visite le site dans un navigateur, tout fonctionne parfaitement.
Le coupable : un service worker qui générait le contenu. Sans lui, les pages internes renvoyaient des erreurs 404. Avec lui, le site tournait comme une horloge. Problème : Googlebot ne l’a jamais exécuté.
En fait, Googlebot ne supporte pas du tout cette fonctionnalité : c’est un angle mort encore trop méconnu des équipes marketing digital. Les service workers, ces scripts qui rendent les sites plus rapides et utilisables hors connexion, sont aujourd’hui au coeur de milliers de Progressive Web Apps (ou PWA, des sites web conçus pour offrir une expérience proche d’une application mobile native). Et pourtant, leur interaction avec les moteurs de recherche reste un sujet largement sous-documenté, y compris chez les professionnels du SEO.
Cet article fait le point sur ce que sont réellement les service workers, pourquoi Google refuse de les prendre en charge, quels problèmes concrets cela pose, et surtout quelles pratiques adopter pour éviter que votre PWA ne disparaisse des résultats de recherche.
Un proxy dans votre navigateur : comprendre le service worker
Pour bien saisir les enjeux SEO, il faut d’abord comprendre ce qu’est un service worker et comment il fonctionne.
Un service worker est un script JavaScript qui s’exécute en arrière-plan dans le navigateur, dans un processus séparé de la page web elle-même. Son rôle principal : agir comme un proxy programmable (un intermédiaire logiciel capable d’intercepter et de modifier les échanges de données) entre le navigateur de l’utilisateur et le réseau. Concrètement, il se place entre votre site et Internet, et peut décider pour chaque requête s’il faut aller chercher la ressource sur le serveur distant, la servir depuis un cache local (un espace de stockage temporaire dans le navigateur), ou même fabriquer une réponse de toutes pièces.
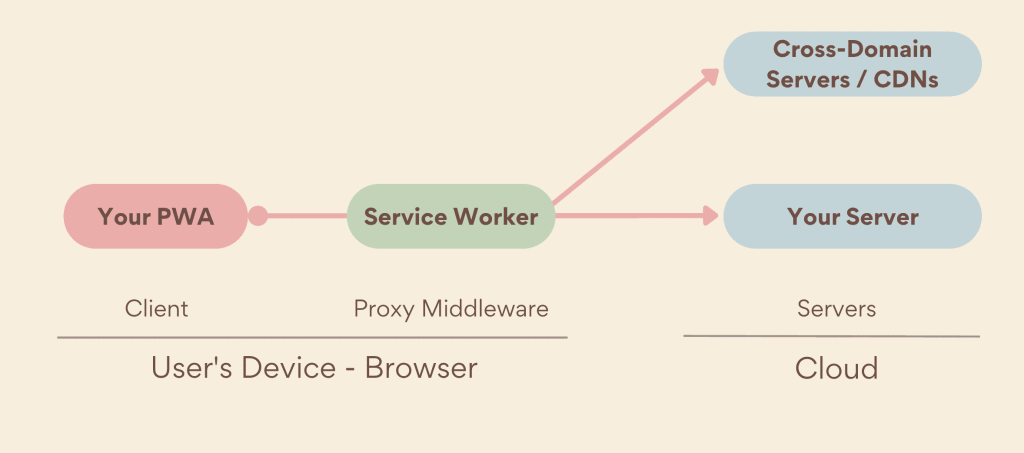
Le point crucial, celui qui explique tout le reste de cet article : un service worker ne fonctionne jamais lors de la première visite. Il doit d’abord être enregistré, installé et activé par la page web. Ce n’est qu’à partir de la visite suivante qu’il peut intercepter les requêtes. Autrement dit, un tout premier visiteur ne bénéficie jamais de ses fonctionnalités.
Autres caractéristiques à retenir : le service worker n’a pas accès au DOM (la structure de la page HTML affichée) et ne peut donc pas modifier directement le contenu visible. Il agit uniquement sur les échanges réseau. Enfin, il exige une connexion HTTPS, puisqu’il a la capacité de modifier des requêtes en transit.
Pourquoi tant de sites les adoptent
Si les service workers posent des questions en matière de SEO, ils n’en restent pas moins une technologie précieuse. Ils constituent la brique technique centrale des PWA et répondent à des besoins concrets des utilisateurs et des équipes produit.
Le mode hors-ligne est sans doute l’usage le plus connu : grâce au service worker, un site web peut continuer de fonctionner sans connexion internet. L’utilisateur consulte un catalogue produit dans le métro, relit un article en avion ou remplit un formulaire en zone blanche. Le service worker puise dans les ressources qu’il a mises en cache lors des visites précédentes.
L’amélioration des performances est l’autre grand bénéfice. En mettant en cache les fichiers fréquemment sollicités (feuilles de style CSS, scripts JavaScript, images, polices de caractères), le service worker permet des temps de chargement quasi instantanés pour les visiteurs réguliers. C’est un levier direct sur les Core Web Vitals, ces indicateurs de performance que Google utilise comme signaux de classement.
Viennent ensuite les notifications push (alertes envoyées même quand l’utilisateur n’est pas sur le site), la synchronisation en arrière-plan (les actions effectuées hors-ligne sont mises en file d’attente et exécutées au retour de la connexion) et les stratégies de cache avancées. Ces dernières permettent au développeur de définir des règles fines : servir le cache d’abord puis rafraîchir en arrière-plan (technique dite du « stale-while-revalidate« ), ou encore toujours tenter le réseau et ne basculer sur le cache qu’en cas d’échec (« network-first« ).
La position de Google : un refus clair et assumé
Venons-en au coeur du problème. Googlebot, le robot d’exploration de Google, ne supporte pas les service workers. Il les désactive purement et simplement lors du crawl. Et ce n’est ni un bug, ni un retard technique : c’est une décision délibérée et documentée.
Martin Splitt a été on ne peut plus explicite sur ce point lorsqu’on lui a demandé sur Reddit si Google prévoyait de prendre en charge les service workers :
« As we have to assume that someone clicking on your page from a SERP is a first-time visitor, running a service worker is usually not going to do much good. »
En 2023, John Mueller, Search Advocate chez Google, a enfoncé le clou sur Mastodon :
« I don’t think anything has changed. I wouldn’t expect it to change – it’s computationally expensive to run service-workers in the background like this for indexing. »
Quatre raisons techniques justifient cette position :
- Le paradigme du premier visiteur. Googlebot simule toujours un utilisateur qui découvre le site pour la première fois. Or, un service worker n’est actif qu’à partir de la deuxième visite. Google ne verra donc jamais son effet.
- Le coût de calcul. Maintenir et exécuter des service workers pour les milliards de pages que Google crawle chaque jour serait extrêmement gourmand en ressources d’infrastructure.
- L’absence d’état persistant. Googlebot est stateless : il ne conserve ni cookies, ni stockage local, ni aucune donnée de session entre deux URLs crawlées. Chaque page est traitée comme une visite vierge.
- La cohérence de l’expérience utilisateur. Google veut que ce qu’il indexe corresponde exactement à ce que verra un internaute cliquant depuis les résultats de recherche, c’est-à-dire un premier visiteur sans service worker actif.
Quatre scénarios qui peuvent vous coûter cher
Les conséquences de cette non-prise en charge ne sont pas théoriques. Voici les problèmes les plus fréquemment observés par les praticiens du SEO technique.
Le contenu fantôme. C’est le scénario le plus grave, celui du cas raconté par Martin Splitt : des pages dont le contenu dépend entièrement du service worker pour s’afficher. Sans lui, le serveur renvoie une page vide ou une erreur. Le site fonctionne pour les utilisateurs réguliers (dont le navigateur a installé le service worker), mais Googlebot ne voit rien. Résultat : zéro indexation, zéro trafic organique.
La divergence de contenu. Un service worker peut modifier à la volée le HTML d’une page, remplacer des images, injecter du contenu dynamique ou altérer les balises meta. Si ces modifications ne sont effectives qu’après activation du service worker, Google voit une version de la page, et les utilisateurs en voient une autre. Un test réalisé par SearchVIU l’a illustré de manière parlante : un service worker remplaçait une image de chat par une licorne sur la même URL. Google ne voyait que le chat.
L’altération des métadonnées SEO. Des service workers mal configurés peuvent, à des fins de cache, modifier ou supprimer des balises canoniques (indiquant la version de référence d’une page), des directives robots (qui guident l’indexation), des hreflang (signalant les versions linguistiques) ou des données structurées (le balisage sémantique lu par les moteurs). Le développeur ne s’en rend pas compte car il navigue avec le service worker actif.
Les audits faussés. Quand un consultant SEO audite un site dans son navigateur habituel, le service worker peut masquer des dysfonctionnements en servant des pages depuis le cache local. Le site semble sain, alors que le serveur renvoie des erreurs. C’est un piège classique qui peut retarder la détection de problèmes critiques.
Les bonnes pratiques pour concilier service worker et référencement
Fort heureusement, les service workers ne sont pas incompatibles avec le SEO. Il suffit de respecter un principe fondamental : le service worker enrichit l’expérience, il ne la fonde pas.

Tout le contenu doit exister sans service worker
C’est la règle d’or, celle qui découle directement du fonctionnement de Googlebot. Le HTML initial renvoyé par votre serveur doit contenir l’intégralité du contenu indexable : texte, images, liens internes, balises meta, canonicals, données structurées, hreflang. Le service worker ne doit jamais être la condition nécessaire à l’affichage du contenu. En ingénierie web, ce principe porte un nom : le progressive enhancement (amélioration progressive). Le site fonctionne pleinement dans sa version de base ; les technologies avancées viennent ajouter du confort, jamais remplacer le socle.
Choisir la bonne stratégie de rendu
Le choix de l’architecture de rendu est déterminant pour les PWA :
- Le SSR (Server-Side Rendering, où le serveur génère le HTML complet à chaque requête) est l’option la plus sûre pour le SEO.
- Le SSG (Static Site Generation, où les pages sont pré-construites en HTML au moment du déploiement) offre d’excellentes garanties d’indexation.
- Le rendu hybride (le serveur envoie un HTML complet, puis le JavaScript côté client « hydrate » la page pour la rendre interactive) est l’approche explicitement recommandée par Martin Splitt. Les frameworks Next.js, Nuxt.js, Angular Universal et SvelteKit supportent cette méthode.
- Le CSR seul (Client-Side Rendering, où tout le contenu est généré par JavaScript dans le navigateur) est à éviter quand le SEO est un enjeu. Google peut le traiter, mais avec un processus d’indexation en deux phases qui introduit un délai et aucune garantie de couverture complète.
Tester systématiquement comme le ferait Googlebot
La vérification régulière est indispensable. Quatre réflexes à intégrer dans votre routine d’audit : naviguer en mode incognito pour bypasser le service worker ; utiliser les Chrome DevTools (onglet Application, puis Service Workers, cocher « Bypass for network ») pour forcer les requêtes vers le réseau ; exploiter l’inspection d’URL dans Google Search Console pour comparer le rendu de Google à ce que vous voyez ; et tester la compatibilité mobile sans dépendance au service worker.
Garder des URLs propres et un sitemap à jour
Ce conseil vaut pour tout site web, mais il prend une importance particulière pour les PWA. Utilisez de vraies URLs, jamais de fragments (les identifiants précédés du caractère #, que Google n’indexe pas). Chaque page doit disposer d’une URL canonique correcte. Maintenez un sitemap XML à jour qui recense toutes les pages de votre PWA. Et vérifiez que votre fichier robots.txt n’interdit pas l’accès aux fichiers CSS et JavaScript nécessaires au rendu.
Maîtriser les stratégies de cache
Dernier point d’attention : si votre service worker met en cache des pages ou des ressources, gardez à l’esprit que Googlebot ne passe jamais par le cache du service worker. Il interroge directement votre serveur. Assurez-vous donc que le serveur renvoie toujours un contenu complet et à jour, indépendamment de ce que le service worker fait pour les utilisateurs humains. Vérifiez aussi que les assets critiques (CSS, JS) ne sont pas modifiés de manière invisible par le cache, ce qui créerait un décalage entre l’expérience utilisateur et le contenu indexé. Enfin, n’oubliez pas que votre page « fallback » hors-ligne ne sera jamais vue par Google : elle est réservée aux utilisateurs.
Ce qu’il faut retenir
Le message est finalement assez simple. Les service workers sont une technologie puissante, utile et largement adoptée. Ils améliorent la performance, permettent le fonctionnement hors-ligne et enrichissent l’expérience des visiteurs réguliers. Mais Googlebot les ignore totalement, et cette situation ne changera pas dans un avenir prévisible.
Pour les professionnels du digital, cela implique une vigilance particulière : tout contenu qui n’existe que grâce au service worker est invisible pour les moteurs de recherche. Le référencement naturel d’une PWA repose sur la qualité de ce que le serveur délivre avant toute intervention du service worker. C’est ce HTML initial, nu, qui sera crawlé, rendu et indexé.
En un mot : faites confiance au service worker pour l’expérience utilisateur, mais ne lui confiez jamais votre SEO.
Bibliographie
- Martin Splitt, via Search Engine Roundtable : Google Search Has No Plans On Supporting Service Workers (2021, mis à jour 2023)
- Sara Taher : Service Workers & SEO (2022)
- SearchVIU : Service Worker – What SEOs Need to Know (2023)
- Dave Smart, Tame the Bots : Web Worker Content – Will It Index? (2021)
- Love2Dev : Do Progressive Web Apps Improve SEO?
- Onely : Rendering SEO: How Google Digests Your Content (2021, transcription du webinaire avec Martin Splitt)
- Search Engine Journal : How Rendering Affects SEO: Takeaways From Google’s Martin Splitt (2025)
- Google : Documentation officielle Googlebot
- Google / web.dev : Bringing service workers to Google Search (case study)
- OnCrawl : Effective SEO techniques for promoting Progressive Web Apps (2024)