
Le 24 septembre 2025, Cloudflare a lancé sa Content Signals Policy, une extension du protocole robots.txt qui pourrait redéfinir l’équilibre de pouvoir entre créateurs de contenu et géants de l’IA. Avec 20% du trafic internet mondial sous sa gestion, l’entreprise ne se contente plus de proposer une solution technique : elle lance un défi direct à Google, dont les AI Overviews agrègent le contenu du web sans toujours générer de trafic de retour vers les sources originales. La question n’est plus de savoir si cette initiative est nécessaire – les chiffres parlent d’eux-mêmes : Cloudflare prédit que le trafic bot dépassera le trafic humain d’ici fin 2029. La vraie interrogation porte sur l’application : Google et les autres acteurs majeurs de l’IA joueront-ils le jeu ?
Le protocole robots.txt face à l’ère de l’IA générative : anatomie d’une obsolescence programmée
Le protocole robots.txt (Robots Exclusion Protocol, standardisé par la RFC 9309) a toujours reposé sur un principe fondamental : il indique aux crawlers – ces programmes automatisés qui parcourent le web pour indexer son contenu – quelles parties d’un site peuvent être visitées. Mais il présente une lacune critique dans le contexte actuel : il ne régule que l’accès au contenu, pas son utilisation après collecte.
Cette distinction devient cruciale quand on comprend la différence entre crawling et indexing. Le crawling désigne le processus de découverte et de visite des pages par les moteurs de recherche. L’indexing, lui, correspond au stockage et à l’organisation de ce contenu dans une base de données pour qu’il puisse apparaître dans les résultats de recherche. Un fichier robots.txt peut empêcher le crawling, mais pas l’indexing – une nuance que même les SEO expérimentés oublient parfois.
Dans l’écosystème traditionnel de la recherche, cette limite n’était pas problématique. Les moteurs de recherche indexaient le contenu, mais renvoyaient du trafic via leurs pages de résultats et généraient de l’attribution pour les créateurs. Un contrat implicite existait : les sites acceptaient d’être crawlés en échange de visibilité et de trafic qualifié. Ce modèle économique a soutenu l’économie du web pendant deux décennies.
L’avènement de l’IA générative a rompu cet équilibre. Les LLM (Large Language Models, ou modèles de langage de grande taille) comme GPT, Claude ou Gemini nécessitent des volumes massifs de données pour leur entraînement. Plus critique encore, les fonctionnalités comme les AI Overviews de Google ou les réponses conversationnelles des chatbots utilisent le contenu web en temps réel via RAG (Retrieval-Augmented Generation, une technique qui enrichit les réponses de l’IA avec des données externes récupérées à la volée) sans nécessairement rediriger l’utilisateur vers la source originale. Le résultat ? Un problème classique de free-rider : les entreprises d’IA extraient de la valeur du contenu web sans compenser les créateurs, ni même leur attribuer correctement la paternité de leur travail.
La Content Signals Policy : trois signaux pour reprendre le contrôle
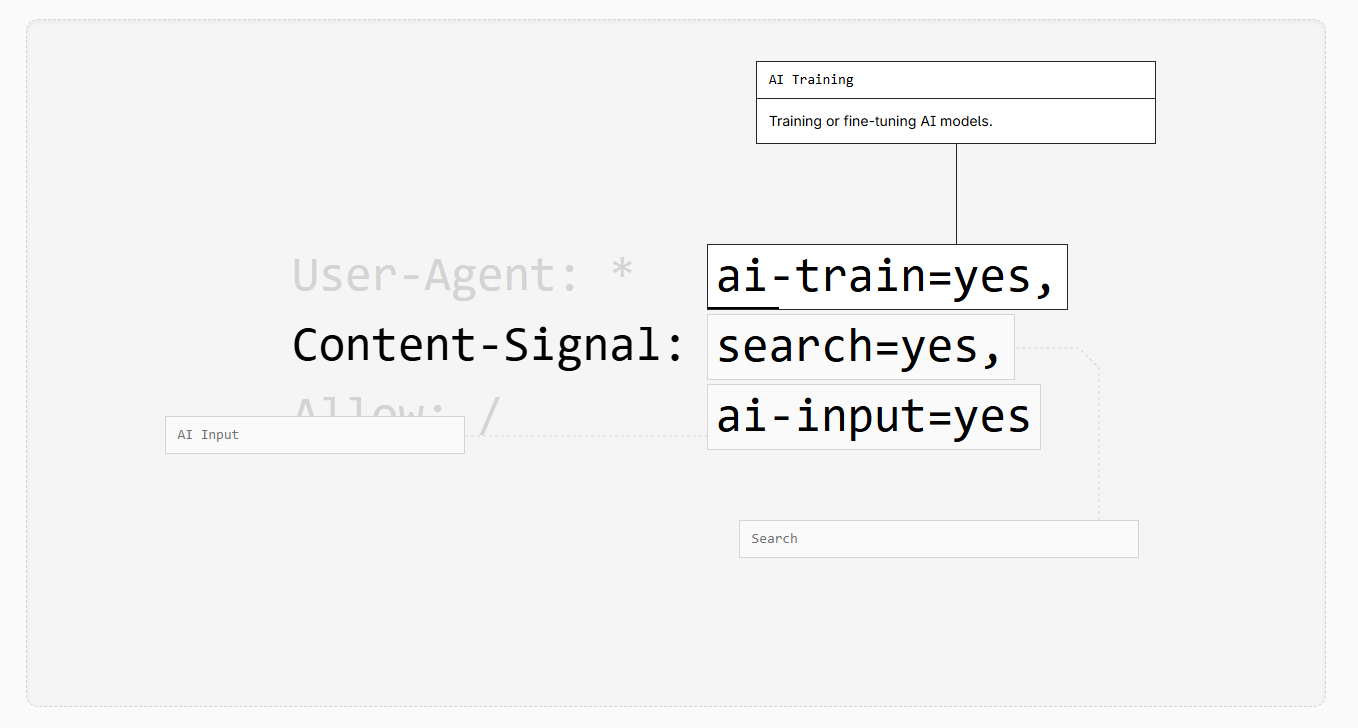
La Content Signals Policy de Cloudflare introduit trois directives distinctes qui étendent le protocole robots.txt au-delà du simple contrôle d’accès. Ces signaux sont intégrés dans le fichier robots.txt sous forme de commentaires (précédés du symbole #), ce qui les rend lisibles par les humains tout en permettant leur interprétation machine via une syntaxe structurée.
Les trois signaux définis :
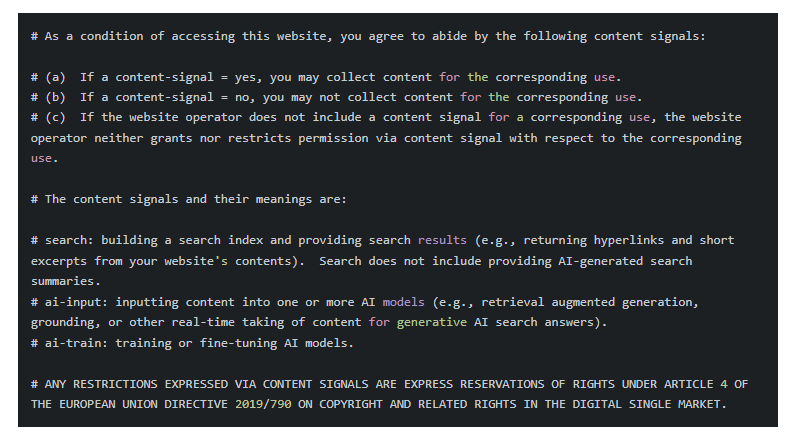
- search : autorise la construction d’un index de recherche et l’affichage de liens avec des extraits courts dans les résultats traditionnels. Ce signal couvre l’usage classique des moteurs de recherche où l’utilisateur clique sur un lien pour accéder au contenu source complet.
- ai-input : gouverne l’utilisation du contenu comme input pour des réponses IA générées en temps réel. Cela inclut les AI Overviews de Google, les réponses de ChatGPT avec navigation web activée, ou toute autre forme de grounding (ancrage de la réponse de l’IA dans des sources externes pour améliorer sa factualité) qui synthétise le contenu sans nécessairement renvoyer vers la source.
- ai-train : contrôle l’utilisation du contenu pour l’entraînement ou le fine-tuning (affinage) de modèles d’IA. Cette distinction est cruciale car elle sépare l’utilisation ponctuelle (ai-input) de l’incorporation permanente dans les paramètres d’un modèle lors de son apprentissage.
Chaque signal accepte trois valeurs : « yes » (autorisation explicite), « no » (interdiction explicite), ou absence de signal (neutralité, sans consentement ni restriction exprimés via ce mécanisme). Cette granularité permet aux éditeurs de définir des politiques nuancées. Un site d’actualité pourrait autoriser search=yes pour maintenir sa visibilité SEO, définir ai-input=no pour protéger son trafic des AI Overviews, et laisser ai-train neutre pour évaluer les opportunités de licences commerciales futures.
Cloudflare a déployé automatiquement ces signaux sur 3,8 millions de domaines utilisant son service de robots.txt géré, avec une configuration par défaut de search=yes et ai-train=no. Le signal ai-input reste délibérément non défini : Cloudflare préfère ne pas présumer des préférences de ses clients sur cette utilisation spécifique, considérant qu’elle représente le point de friction le plus sensible entre visibilité et monétisation.
La politique inclut également une clause juridique importante : « ANY RESTRICTIONS EXPRESSED VIA CONTENT SIGNALS ARE EXPRESS RESERVATIONS OF RIGHTS UNDER ARTICLE 4 OF THE EUROPEAN UNION DIRECTIVE 2019/790 ». Cette référence à la Directive européenne sur le droit d’auteur dans le marché unique numérique vise à transformer ces signaux techniques en déclarations juridiquement significatives, renforçant la position légale des éditeurs en cas de litige.
Le talon d’Achille de Google : pourquoi Googlebot pose un problème unique
Matthew Prince, PDG de Cloudflare, ne mâche pas ses mots : « Chaque moteur de réponse IA devrait jouer selon les mêmes règles. Google combine son crawler pour la recherche avec ses moteurs de réponse IA, ce qui leur donne un avantage unique et déloyal. » Cette critique cible une asymétrie fondamentale dans l’architecture technique de Google.
Contrairement à OpenAI qui utilise des crawlers distincts pour la recherche (via des partenariats) et pour l’entraînement de ses modèles, Google utilise Googlebot – son crawler historique – à la fois pour l’indexation traditionnelle et pour alimenter ses fonctionnalités IA. Techniquement, Google propose Google-Extended, un user-agent séparé que les sites peuvent bloquer pour opt-out de l’entraînement des modèles Gemini. Mais lors du procès antitrust US v. Google, un cadre de DeepMind a confirmé qu’un contenu bloqué pour Google-Extended pouvait encore être utilisé par la division Search, incluant potentiellement les AI Overviews.
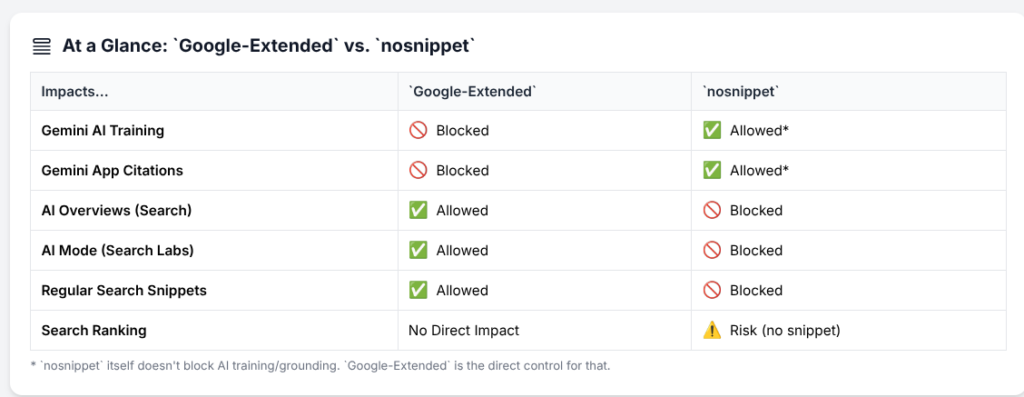
Cette architecture met les éditeurs face à un dilemme cornélien : bloquer Google-Extended pour protéger leur contenu de l’entraînement IA, tout en sachant que leurs pages peuvent toujours alimenter les AI Overviews via Googlebot. Ou plus dramatique encore : bloquer Googlebot entièrement et renoncer à 90% de leur trafic organique dans de nombreuses régions. C’est un choix binaire entre visibilité et contrôle, exactement ce que la Content Signals Policy cherche à résoudre en permettant une granularité plus fine.
Le silence de Google sur son intention de respecter ces nouveaux signaux n’est pas anodin. Lors d’une conférence avec des investisseurs, un analyste a demandé à Sundar Pichai si Google honorerait les Content Signals. La réponse est restée évasive, se limitant à rappeler l’engagement de Google envers « des pratiques responsables » sans commitment spécifique. Ce flou stratégique suggère que Google évalue encore comment équilibrer son avantage concurrentiel dans l’IA avec les pressions réglementaires croissantes, particulièrement en Europe où la RGPD et la Directive Copyright créent un environnement juridique plus contraignant.
Microsoft, les autres acteurs IA, et le grand silence radio
Du côté de Microsoft, l’absence de réaction publique à la Content Signals Policy est tout aussi révélatrice. Bing utilise également un crawler unique (Bingbot) pour l’indexation et pour alimenter Copilot, son assistant IA qui génère des réponses synthétiques. La situation est structurellement similaire à celle de Google, même si la part de marché moindre de Bing (environ 3% globalement) rend l’enjeu moins critique pour les éditeurs.
Microsoft a récemment mis l’accent sur son Consent Mode pour la publicité, imposant aux annonceurs de fournir des signaux de consentement utilisateur d’ici mai 2025 pour se conformer au RGPD. Cette initiative montre une sensibilité aux questions de consentement, mais elle concerne les données utilisateurs, pas les droits des créateurs de contenu. Aucune déclaration de Microsoft n’indique une volonté d’adopter les Content Signals pour Bing Search ou Copilot.
Les pure-players de l’IA – OpenAI, Anthropic, Perplexity – n’ont pas non plus réagi officiellement. OpenAI utilise déjà des crawlers séparés (GPTBot pour l’entraînement, SearchGPT-bot pour son moteur de recherche), une architecture qui s’alignerait naturellement avec la philosophie des Content Signals. Anthropic déploie Claude-bot, également distinct de ses services de recherche via des partenariats. Ces entreprises ont théoriquement moins à perdre en adoptant les nouveaux signaux.
Le cas Perplexity mérite une mention particulière. Cloudflare a publiquement accusé l’entreprise en juillet 2025 d’utiliser des « stealth crawlers » (crawlers furtifs) qui se font passer pour des navigateurs humains pour contourner les restrictions robots.txt. Perplexity a vigoureusement démenti, affirmant respecter les directives d’exclusion. Cette controverse illustre le cœur du problème : sans mécanisme d’application technique, même les signaux les plus clairs restent vulnérables aux acteurs malveillants ou à ceux qui choisissent de les ignorer pour des raisons stratégiques.
L’IETF et la standardisation
L’initiative de Cloudflare ne se déroule pas dans le vide. Un groupe de travail de l’IETF (Internet Engineering Task Force, l’organisme de standardisation de l’internet) nommé AI Preferences travaille depuis début 2024 sur des mécanismes standardisés pour exprimer les préférences d’utilisation du contenu. Leur objectif : définir un vocabulaire commun au-delà de robots.txt.

Les discussions techniques révèlent la complexité du défi. Comment gérer la composabilité des préférences ? Un site pourrait vouloir autoriser l’indexation pour la recherche IA mais pas l’entraînement, ou permettre l’entraînement uniquement dans certaines juridictions, ou imposer des embargos temporels (autorisation après X mois). Comment interpréter l’absence de signal ? Par défaut, est-ce un consentement implicite ou une restriction implicite ?
L’IETF favorise généralement des approches neutres : l’absence de signal ne devrait conférer ni permission ni interdiction. Mais cette position renforce le statu quo où les entreprises d’IA interprètent le silence comme un consentement tacite. Les organisations de créateurs et les éditeurs, notamment la News/Media Alliance, poussent pour une interprétation plus protectrice : l’absence de signal explicite devrait nécessiter une négociation ou au minimum un opt-in actif.
Cloudflare a publié sa Content Signals Policy sous licence CC0 (Creative Commons Zero), renonçant à tous ses droits pour encourager l’adoption universelle. Cette stratégie de standardisation de facto vise à créer un momentum avant même que l’IETF n’ait finalisé une spécification officielle. Si suffisamment d’acteurs majeurs adoptent les Content Signals, elles pourraient devenir le standard de facto que l’IETF devra ensuite ratifier.
Pourquoi les éditeurs sont (prudemment) optimistes
Danielle Coffey, présidente de la News/Media Alliance qui représente des milliers d’éditeurs américains, salue l’initiative : « Nous sommes ravis que Cloudflare offre un nouvel outil puissant, désormais largement accessible à tous les utilisateurs, permettant aux éditeurs de dicter comment et où leur contenu est utilisé. C’est une étape importante vers l’autonomisation des éditeurs de toutes tailles. »
Cette approbation masque néanmoins des inquiétudes persistantes. Lors d’entretiens menés par Digiday avec plusieurs responsables d’éditeurs majeurs, le sentiment dominant est celui d’un « progrès nécessaire mais insuffisant ». Un directeur de publication d’un grand groupe de presse, s’exprimant anonymement, résume : « C’est comme poser un panneau ‘Défense d’entrer’ devant une porte ouverte. Mieux que rien, mais sans verrou, ça reste symbolique. »
Les éditeurs doivent également naviguer dans un environnement stratégique complexe. Condé Nast, News Corp, Axel Springer et d’autres ont signé des accords de licensing directement avec OpenAI et d’autres acteurs de l’IA, monétisant leur contenu contre des sommes substantielles (de l’ordre de dizaines de millions de dollars sur plusieurs années). Pour ces acteurs, les Content Signals représentent un levier de négociation : ils peuvent menacer de bloquer l’accès via les signaux pour obtenir de meilleures conditions commerciales.
À l’inverse, les éditeurs de taille moyenne et les sites de niche manquent de pouvoir de négociation pour des deals individuels. Pour eux, les Content Signals offrent au moins un moyen de s’opposer collectivement, en espérant que l’accumulation de restrictions finira par forcer les acteurs IA à proposer des conditions générales plus équitables ou à respecter les opt-outs.
Stack Overflow illustre un cas d’usage particulier. La plateforme a construit un corpus massif de Q&A techniques qui est devenu essentiel pour l’entraînement de modèles de code comme GitHub Copilot ou Claude. Son CEO Prashanth Chandrasekar applaudit Cloudflare « pour jouer un rôle central dans l’autonomisation et la protection des créateurs de contenu dans cette nouvelle ère de l’IA », tout en développant en parallèle OverflowAI, son propre produit basé sur l’IA qui monétise directement ce corpus. La position est pragmatique : participer à l’écosystème IA tout en contrôlant strictement comment les autres utilisent les données.
Les scénarios pour 2026-2027 : entre utopie collaborative et guerre des données
Plusieurs futurs sont possibles pour la Content Signals Policy. Le scénario optimiste repose sur l’effet d’entraînement et la pression réglementaire. Si suffisamment d’acteurs majeurs adoptent les signaux, le coût réputationnel et juridique de les ignorer deviendrait prohibitif. L’AI Act européen et le Digital Services Act créent déjà des obligations de transparence sur les données d’entraînement. Une future révision pourrait explicitement requérir le respect des Content Signals comme condition d’opération dans l’UE.
Dans ce scénario, Google finirait par séparer techniquement Googlebot en plusieurs user-agents distincts – un pour l’indexation traditionnelle, un autre pour les AI Overviews, un troisième pour l’entraînement de Gemini. Les éditeurs pourraient alors définir des politiques granulaires, restaurant un équilibre entre visibilité et contrôle. Un écosystème de licensing émergérait, avec des plateformes comme le Pay Per Crawl de Cloudflare facilitant les transactions à grande échelle.
Le scénario pessimiste est celui d’une course aux armements technologiques. Les acteurs IA développeraient des crawlers de plus en plus sophistiqués pour contourner les restrictions – utilisant du browser fingerprinting pour se faire passer pour des visiteurs humains, distribuant le crawling sur des millions d’IP résidentielles via des residential proxies, ou exploitant des vulnérabilités dans les systèmes de détection de bots. Cloudflare et d’autres répondraient avec des outils toujours plus agressifs, créant un internet fragmenté où le trafic légitime lui-même subirait des frictions.
Le scénario intermédiaire – et probablement le plus réaliste – est une segmentation du marché. Les acteurs IA « responsables » (probablement sous pression réglementaire en Europe et via des accords volontaires aux États-Unis) respecteraient les Content Signals, tandis qu’une frange d’acteurs moins scrupuleux ou offshore les ignorerait. Les grands éditeurs et les sites populaires bénéficieraient d’une protection effective via les outils techniques de Cloudflare et d’autres providers de sécurité. Les sites plus petits, sans ressources pour implémenter des défenses sophistiquées, resteraient vulnérables.
Cloudflare prévoit que le trafic bot dépassera le trafic humain d’ici fin 2029, et qu’en 2031, l’activité des bots dépassera à elle seule la totalité du trafic internet actuel. Ces projections incluent à la fois les bots légitimes (crawlers de recherche, monitoring, CDN) et les bots problématiques (scraping, attaques DDoS, fraude publicitaire). Si même 30% de ce trafic bot concerne le data scraping pour l’IA, l’ampleur du phénomène justifie des mécanismes de contrôle beaucoup plus robustes que le robots.txt historique.
Implications SEO : repenser les workflows en 2025
Pour les professionnels SEO, les Content Signals Policy introduisent de nouvelles dimensions dans l’optimisation et la stratégie de contenu. Le crawl budget – cette ressource limitée de combien de pages Googlebot crawle sur un site dans un temps donné – doit désormais être pensé en incluant les crawlers IA qui peuvent être beaucoup plus gourmands.
Les sites à fort volume de contenu généré par utilisateurs (UGC) font face à des choix stratégiques. Reddit a pris une position radicale en bloquant tous les crawlers IA sauf Google (avec qui il a signé un accord de licensing). Cette décision reflète un calcul simple : le trafic organique venant de Google vaut plus que la valeur d’entraînement du contenu pour d’autres acteurs. D’autres plateformes de niche pourraient suivre, créant des « walled gardens » de données accessibles uniquement via des partenariats commerciaux.
L’implémentation technique des Content Signals est relativement simple pour un site moderne. Le fichier robots.txt, servi à domain.com/robots.txt, inclut simplement les lignes de politique en commentaire puis les signaux machine-readable :
# Content Signals Policy (texte complet de la politique)
User-Agent: *
Content-Signal: search=yes, ai-train=no, ai-input=no
Allow: /
Mais la simplicité technique masque des décisions stratégiques complexes. Un site de recettes devrait-il bloquer ai-train pour préserver l’unicité de ses recettes, tout en autorisant ai-input pour apparaître dans les réponses de ChatGPT aux questions culinaires ? Un blog technique devrait-il autoriser l’entraînement pour maximiser l’influence de ses idées dans l’écosystème IA, pariant sur la visibilité long-terme plutôt que le trafic immédiat ?
Les outils SEO devront évoluer. Google Search Console ne fournit actuellement aucune visibilité sur comment le contenu d’un site est utilisé dans les AI Overviews – combien d’impressions, quel taux de citation, quel impact sur le CTR organique. Si Google adopte les Content Signals, ces métriques deviendraient essentielles pour optimiser les trade-offs entre visibilité IA et trafic direct.
Le rôle clé du RSL Collective et l’émergence des standards de licensing
Le RSL Collective (Responsible Sourcing of Learning data), mentionné dans le communiqué de Cloudflare, représente une autre approche complémentaire. Fondé par un consortium d’éditeurs majeurs, le RSL développe un standard machine-readable pour les termes de licensing et de compensation liés à l’utilisation de contenu pour l’IA.
Là où les Content Signals Policy expriment des préférences binaires (oui/non), le RSL standard permet de définir des conditions complexes : « Vous pouvez utiliser ce contenu pour l’entraînement IA moyennant 0,002$ par token traité, avec attribution obligatoire, limité à des modèles non-commerciaux, ou sous licence commerciale à négocier pour usage commercial. » Ces métadonnées, intégrées dans les headers HTTP ou dans des fichiers sidecar JSON, transforment chaque page web en un mini-contrat de licensing.
L’interopérabilité entre Content Signals et RSL est intentionnelle. Cloudflare et le RSL Collective travaillent conjointement pour que les deux systèmes se complètent : Content Signals pour l’opt-in/opt-out de base, RSL pour les conditions commerciales détaillées. Un crawler respectueux lirait d’abord le robots.txt avec les Content Signals, puis si ai-train=yes, consulterait les métadonnées RSL pour comprendre les termes d’usage.
Ce modèle en deux couches pourrait résoudre le dilemme économique de l’entraînement IA. Les entreprises d’IA obtiendraient l’accès aux données dont elles ont besoin, les créateurs seraient rémunérés équitablement, et le processus serait suffisamment automatisé pour être scalable. Les smart contracts sur blockchain ont même été évoqués pour automatiser les paiements par token consommé, bien que cette approche reste expérimentale.
Vers un nouveau paradigme : de l’open web au licensed web ?
Certains critiques, comme Cory Doctorow dans son essai sur l’enshittification du web, argumentent que les Content Signals Policy accélèrent une tendance inquiétante : la fermeture progressive du web ouvert. Si chaque site exige des négociations de licensing pour toute utilisation IA, le coût transactionnel pourrait privilégier les quelques géants capables de payer, étouffant l’innovation par les startups et les projets académiques.
Ce risque est réel. Common Crawl, la fondation qui maintient des archives publiques massives du web utilisées par d’innombrables projets de recherche en NLP, devrait-elle respecter les Content Signals ? Si oui, ces archives deviendraient potentiellement beaucoup moins complètes. Les chercheurs académiques, qui ne peuvent pas payer des millions pour des accords de licensing avec des milliers d’éditeurs, perdraient l’accès à des données cruciales pour faire progresser la science.
Anthropic, dans sa réponse au AI Action Plan de la Maison Blanche, plaide pour un équilibre : protéger les droits des créateurs tout en préservant l’accès aux données pour l’innovation, notamment via des exemptions claires pour l’usage académique et la recherche. OpenAI, de son côté, a lobbying activement pour que le fair use américain couvre l’entraînement IA, arguant que les modèles transforment suffisamment les données pour ne pas constituer une violation de copyright.
Le débat juridique sur le fair use dans le contexte de l’IA n’est pas tranché. The New York Times v. OpenAI et d’autres procès en cours établiront des précédents majeurs. Si les tribunaux américains décident que l’entraînement IA constitue un fair use, les Content Signals auraient peu de poids légal aux États-Unis (bien qu’ils resteraient pertinents en Europe sous la Directive Copyright). À l’inverse, si les tribunaux exigent un licensing explicite, les Content Signals deviendraient le mécanisme par défaut pour l’exprimer.
Recommandations tactiques pour les marketers et SEO
À court terme, les professionnels du digital marketing devraient :
Auditer et décider : Évaluer la valeur stratégique du contenu de chaque site sous gestion. Le contenu evergreen à forte valeur ajoutée mérite-t-il une protection stricte contre l’entraînement IA ? Les contenus informationnels grand public bénéficieraient-ils d’une visibilité maximale dans les réponses IA ?
Implémenter les signaux de manière réfléchie : Ne pas se contenter du default de Cloudflare. Définir une stratégie par type de contenu. Un site e-commerce pourrait autoriser search=yes et ai-input=yes (pour apparaître dans les recommandations d’assistants shopping) mais bloquer ai-train=no (pour protéger les descriptions de produits uniques).
Monitorer l’adoption : Suivre les déclarations de Google, Microsoft et autres acteurs majeurs. Si Google annonce le respect des Content Signals, l’implémentation devient prioritaire. Si les signaux sont ignorés, investir plutôt dans des outils techniques d’enforcement.
Tester l’impact : Implémenter les signaux de manière progressive par section de site, mesurer l’impact sur le trafic organique, les impressions dans les AI features, et le trafic referral. Les données réelles guideront l’optimisation.
Se préparer aux alternatives : Explorer les outils de bot management de Cloudflare, Akamai, ou autres CDN. Évaluer si les fonctionnalités comme AI Labyrinth ou les règles WAF personnalisées apportent une couche de protection supplémentaire justifiant leur coût.
Considérer les opportunités de licensing : Pour les sites disposant de contenus à haute valeur (données propriétaires, recherches originales, contenu expert), explorer les accords directs avec les acteurs IA. Les Content Signals Policy peuvent servir de point de départ pour ces négociations.
À moyen terme, une veille réglementaire est essentielle. L’évolution de l’AI Act, les décisions de justice sur le fair use, et les futures régulations aux États-Unis et en Asie redessineront le paysage. Les marketers data-driven devraient développer des scénarios stratégiques pour s’adapter rapidement à ces changements.
Bibliographie et ressources pour approfondir
Documents officiels et annonces :
- Giving users choice with Cloudflare’s new Content Signals Policy – L’annonce officielle détaillant l’architecture technique et la philosophie de la politique
- Content Signals Policy Generator – Outil officiel de Cloudflare pour générer et déployer les signaux
- RFC 9309 : Robots Exclusion Protocol – La spécification technique officielle du protocole robots.txt standardisée par l’IETF
Analyses techniques et juridiques :
- Robots.txt Is Having a Moment: Here’s Why We Should Care – Analyse approfondie du groupe de travail IETF AI Preferences et des enjeux de standardisation
- EU Copyright Directive 2019/790 – Le texte complet de la directive européenne sur le copyright qui fournit le fondement juridique aux Content Signals
- Robots.txt in 2025: The Death of Goodwill on the Web – Perspective critique sur les limites du modèle volontaire et l’évolution vers des mécanismes cryptographiques
Perspectives de l’industrie :
- Cloudflare updates robots.txt for the AI era – but publishers still want more bite against bots – Interviews de directeurs de publication sur leurs attentes et inquiétudes
- WinBuzzer: Cloudflare Overhauls Web’s AI Rulebook with New Robots.txt ‘Content Signals’ – Analyse technique des implications pour les gestionnaires de CDN et infrastructure
- Cloudflare Pushes Back Against Google’s AI Overviews – Focus sur la confrontation stratégique entre Cloudflare et Google
Recherche académique et technique :
- IETF AI Preferences Working Group – Page officielle du groupe de travail sur les préférences IA à l’IETF, documents de travail et minutes de réunions
- Stanford CRFM Foundation Model Transparency Index – Évaluation de la transparence des principaux modèles de fondation sur leurs données d’entraînement
- Content Provenance and Authenticity Working Group – Initiative C2PA sur l’authenticité du contenu et les watermarks numériques, complémentaire aux Content Signals
Outils et implémentation pratique :
- Cloudflare Bot Management Documentation – Guide technique complet pour combiner Content Signals avec des outils d’enforcement actifs
- Google Search Central: Verifying Googlebot – Méthodes pour vérifier l’authenticité des crawlers Google et détecter les usurpateurs
- SEO Robots.txt Guide 2025 – Guide pratique complet sur l’optimisation robots.txt à l’ère de l’IA générative