

Le rideau vient de tomber sur l’un des procès technologiques les plus scrutés de la décennie. Le Department of Justice américain contre Google a livré bien plus qu’un verdict juridique : une fenêtre sans précédent sur les rouages intimes de l’algorithme qui gouverne 90% des recherches mondiales.
Si certaines informations avaient déjà été révélées lors des témoignages de fin 2023 (notamment sur Navboost et Glue), les documents de clôture du procès apportent des précisions techniques inédites et révèle officiellement des mécanismes que Google gardait secrets.
Les véritables nouveautés incluent :
- l’architecture détaillée du système DocID et ses signaux multiples,
- les précisions sur RankEmbed BERT
- des précisions sur l’utilisation des données Chrome,
- les détails sur l’écosystème IA (GCC, MAGIT, FastSearch),
- et une déclaration sur la prédominance des signaux on-page vs PageRank.
Entre nouvelles révélations sur l’IA et confirmations de systèmes algorithmiques soupçonnés, ces documents transforment notre compréhension du référencement naturel et redéfinissent les priorités stratégiques pour 2025.
L’apprentissage continu : quand chaque interaction sert à entrainer l’algorithme
Selon les documents du procès, « l’apprentissage à partir des user feedbacks des utilisateurs est peut-être la façon centrale dont le classement web s’est amélioré pendant 15 ans. »
Concrètement, chaque recherche génère ce que Google appelle des « exemples d’entraînement ». Le système considère chaque interaction comme « un retour d’information parfaitement clair : ce résultat de recherche est meilleur que celui-là. » Plus fascinant encore, Google peut littéralement « mémoriser » quels résultats sont réellement bons pour des requêtes spécifiques.
Cette approche révèle que l’objectif prioritaire devrait être de créer du contenu que les utilisateurs trouvent réellement utile. Les guidelines de contenu utile de Google ne constituent pas une checklist de facteurs de ranking, mais plutôt des conseils généraux sur ce que les utilisateurs trouvent habituellement pertinent. Les actions des utilisateurs enseignent continuellement à Google quels résultats sont utiles.
Source : Massimiliano Geraci
Cette philosophie, confirmée officiellement dans les documents de clôture, transforme notre compréhension du machine learning appliqué à la recherche. Le machine learning, ou apprentissage automatique, désigne la capacité d’un système informatique à apprendre et s’améliorer automatiquement à partir de données, sans programmation explicite. Ici, nos comportements de recherche alimentent directement l’amélioration algorithmique.
DocID : l’identifiant numérique attribué à chaque page web
Au cœur du système Google se trouve une architecture fascinante : le DocID. Chaque page web indexée reçoit un identifiant unique accompagné d’une constellation de signaux que les ingénieurs appellent « métadonnées » ou « attributs ».

Le DocID était déjà signalé dans le premier papier scientifique de Page et Brin sur le pagerank en 1998
Le DocID, concept hérité des premiers travaux sur PageRank, stocke désormais une richesse d’informations cruciales :
- signaux de popularité mesurés via l’intention utilisateur, les clics, et des systèmes internes comme Navboost et Glue ;
- métriques de qualité incluant l’évaluation de l’autorité thématique ;
- données temporelles comme la première découverte par Googlebot et le dernier crawl effectué ;
- score de spam assigné algorithmiquement ;
- flags techniques pour le type d’appareil et autres signaux spécifiques
Cette approche multi-signaux révèle pourquoi Google peut traiter des milliards de pages avec une précision remarquable. Chaque document porte son « ADN algorithmique » complet, permettant des comparaisons instantanées entre résultats potentiels.
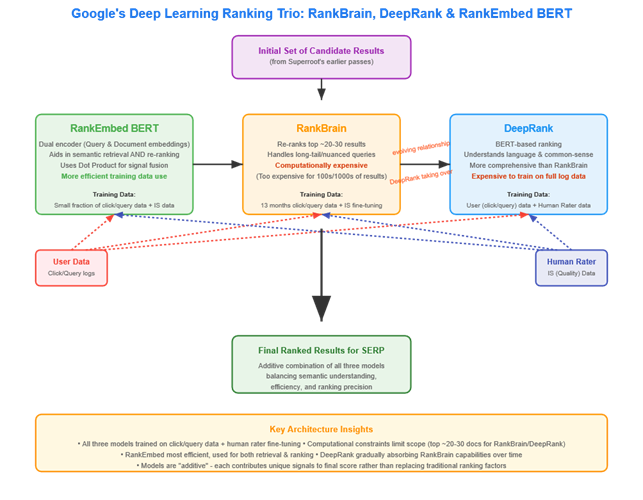
Les signaux de ranking : au-delà des clics directs
Le procès dévoile une architecture de signaux sophistiquée à plusieurs niveaux. Les signaux bruts incluent le nombre de clics, le contenu lui-même, et les termes utilisés dans les requêtes. Cependant, une nuance fondamentale émerge concernant les clics.
Les clics ne constituent pas un facteur de ranking direct. Plutôt, les clics qu’une page reçoit sont stockés et peuvent être utilisés de multiples façons dans des systèmes qui aident à déterminer les rankings, notamment Navboost.
Les signaux de haut niveau comprennent la qualité générale, la popularité, et les signaux dérivés des modèles d’apprentissage profond comme RankEmbed BERT. Tous ces signaux peuvent être agrégés pour créer encore plus de signaux, qui ensemble génèrent un score final pour le ranking.
Navboost, système déjà révélé lors des témoignages de 2023 mais détaillé dans les documents de clôture, associe les requêtes et les documents en mémorisant les données de clics. Considéré comme « très important », Navboost s’entraîne sur 13 mois de données utilisateur (contre 18 mois avant 2017), ce qui équivaut à plus de 17 ans de données sur Bing selon les calculs Google.
Parallèlement, QBST (Query Salient Based Terms), également confirmé dans les révélations antérieures, aide à répondre aux requêtes en identifiant les mots et paires de mots qui « devraient apparaître en bonne place sur les pages web pertinentes pour cette requête ». Ce système s’entraîne sur 13 mois de données utilisateur, illustrant l’utilisation intensive des comportements de recherche dans l’optimisation algorithmique.
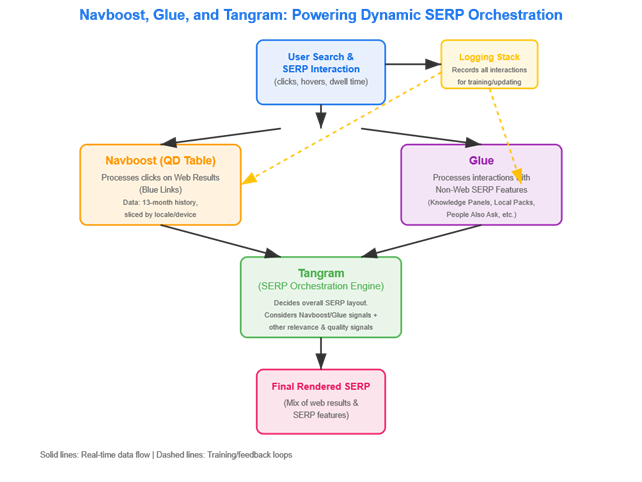
Glue : nouvelles précisions sur le système de tracking
Glue, déjà révélé lors des témoignages de fin 2023, reçoit dans les documents de clôture des précisions techniques supplémentaires. Ce système, décrit comme « une énorme table d’activité utilisateur », collecte une quantité phénoménale de données comportementales en temps réel.
Glue enregistre le texte exact de chaque requête, la langue et localisation de l’utilisateur, le type d’appareil utilisé, tout ce qui apparaît dans les SERP (Search Engine Results Pages), ce sur quoi l’utilisateur clique ou survole, combien de temps il reste sur la SERP, les interprétations de requêtes et suggestions incluant les corrections orthographiques et termes saillants.
Source : Massimiliano Geraci
Google apprend littéralement de chaque recherche. Les systèmes prédisent quels résultats les utilisateurs trouveront utiles – pas seulement les sites web, mais aussi les fonctionnalités SERP comme les AI Overviews, listings maps, People Also Ask et plus. Ensuite, ils mesurent comment les utilisateurs interagissent réellement avec ces résultats. Les systèmes de machine learning continuent d’apprendre pour mieux prédire ce que les chercheurs trouveront probablement utile.
RankEmbed BERT : précisions sur un système déjà identifié
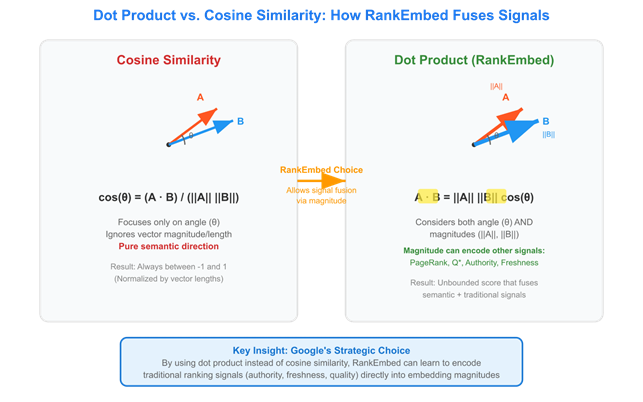
Le procès apporte des détails supplémentaires sur RankEmbed BERT, modèle d’intelligence artificielle spécialisé dans le ranking déjà mentionné dans les révélations antérieures. BERT (Bidirectional Encoder Representations from Transformers) représente une famille d’algorithmes de traitement du langage naturel capable de comprendre le contexte et les nuances linguistiques.
Les documents de clôture précisent que RankEmbed BERT utilise 70 jours de logs de recherche et les scores des Quality Raters qui suivent des guidelines détaillées pour évaluer l’expertise, l’autorité et la fiabilité des pages. C’est un système d’apprentissage profond avec une forte compréhension du langage naturel, permettant au modèle d’identifier plus efficacement les meilleurs documents à récupérer, même si une requête manque de certains termes.
Source : Massimiliano Geraci
Remarkablement, RankEmbed est entraîné sur 1/100ème des données utilisées pour entraîner les modèles de ranking précédents, tout en fournissant des résultats de recherche de qualité supérieure. Cette efficacité s’inscrit dans une tendance déjà identifiée : les signaux de classement plus récents développés par Google (RankBrain, DeepRank, RankEmbed, RankBERT et MUM) reposent moins sur les données utilisateur que les systèmes traditionnels comme Navboost.
Ces systèmes, qualifiés de « généralisation », ne sont « peut-être pas très bons pour mémoriser des faits, mais ils sont vraiment bons pour comprendre le langage ». Ils sont conçus pour combler les lacunes dans les données de clics, permettant à Google de généraliser depuis des situations où il dispose de données vers des situations où il n’en dispose pas. Cruciale précision : ces nouveaux systèmes n’ont pas remplacé Navboost et QBST, qui restent des composants de classement puissants.
Les Quality Raters ne sanctionnent pas directement un site. Au lieu de cela, leur feedback collectif enseigne aux modèles d’IA à quoi ressemblent les « bons » et « mauvais » résultats, ce qui peut influencer comment un site est classé à l’avenir.
La révolution post-PageRank : la page web elle-même domine
La révélation la plus intéressante concerne l’importance actuelle du PageRank.
Les propos du Dr. James Allan, expert Google en informatique et recherche d’information à propos du Pakerank ont été rapportés dans le document de clôture : « Est-ce que vous comprenez bien que la plupart des signaux de qualité de Google sont dérivés de l’analyse de la page web elle-même ? » (sous entendu : pas de signaux externes).
Cette déclaration marque un tournant historique. Le PageRank n’est désormais qu’« un signal unique relatif à la distance depuis une source connue comme faisant autorité. » . Cette déclaration semble faire allusion au calcul d’un Pagerank avec la méthodologie « nearest seeds » (plus on est loin d’une source qui fait autorité, moins le lien transmet de linkjuice). Aujourd’hui, le PageRank n’est qu’un signal parmi beaucoup d’autres utilisés dans le ranking. En fait, ce n’est pas le plus important.
Cette évolution révèle que les liens restent une composante de la qualité, mais ils pâlissent en comparaison des signaux que le site web lui-même envoie. Les signaux les plus importants sont probablement les clics sur cette page, et les signaux provenant des modèles d’apprentissage profond comme RankEmbedBERT qui apprennent continuellement à prédire quelles pages sont susceptibles d’être le meilleur résultat pour la requête d’un chercheur.
Fréquence de crawl : confirmation officielle d’un mécanisme soupçonné
Les documents de clôture confirment officiellement ce qui avait été révélé lors des témoignages : la détermination de la fréquence de crawl par les données utilisateur. Google « a continuellement déployé les données utilisateur pour, entre autres, déterminer quels sites web crawler, dans quel ordre, et à quelle fréquence. »
La fréquence de crawl est déterminée par les signaux de qualité et de popularité. Chaque site possède un score de spam qui est également considéré pour le crawling.
Si Google crawle moins souvent, cela peut signaler un besoin d’améliorer la qualité ou de développer davantage une audience qui recherche activement le contenu. Les statistiques de crawl-purpose montrent combien de ressources sont dépensées pour crawler l’ancien contenu versus découvrir le nouveau contenu produit.
Si Google crawle fréquemment un site pour découvrir du nouveau contenu, c’est probablement très positif.
Chrome Data : la confirmation officielle
Les documents du procès confirment officiellement ce que la communauté SEO soupçonnait : Google utilise les données Chrome dans le ranking. Les documents mentionnent que la popularité est basée sur les « données de visite Chrome » et « le nombre d’ancres. »
Cette révélation suggère que la popularité peut provenir des liens OU des personnes qui visitent et utilisent réellement le site, ce dernier étant plus important. Quelle meilleure représentation de l’utilité d’une page : qu’elle ait des liens, ou que les gens s’engagent activement avec la page, soumettent des formulaires, scrollent, et achètent des produits ?
Google ne mesure pas nécessairement ces activités spécifiques dans Chrome, mais il n’y a aucune raison qu’ils ne le fassent pas. Ils ne seraient probablement pas des facteurs de ranking directs, mais plutôt des signaux utilisés pour déterminer quelles pages les chercheurs trouvent utiles.
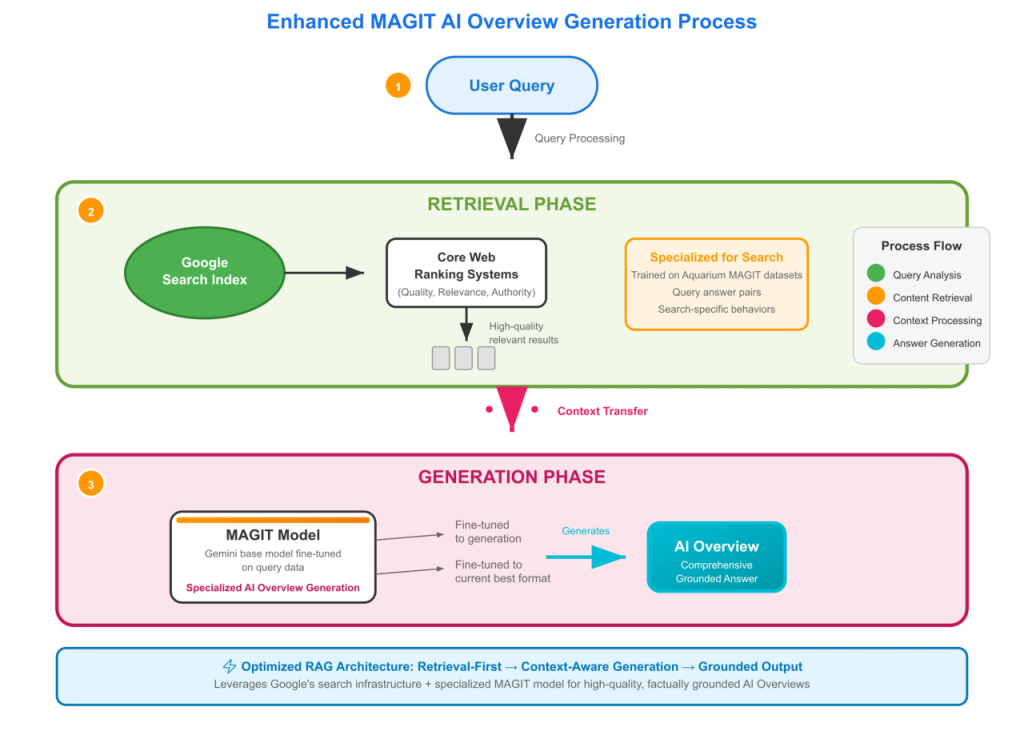
L’écosystème IA : architecture et entraînement
Le volet intelligence artificielle du document de clôture révèle une architecture complexe alimentant les fonctionnalités IA de Google. Google Common Corpus (GCC) constitue la source principale d’entraînement des modèles Gemini, distinct du Common Crawl public. Le GCC implique de grandes quantités d’informations scrapées du web et stockées dans un repository appelé « Docjoins », contenant des documents « visités au moins une fois par Googlebot ces derniers mois. »
MAGIT, version spécialisée de Gemini, est fine-tunée spécifiquement pour produire les textes des AI Overviews. Gemini s’entraîne sur du texte, principalement du web, puis est fine-tuné sur des collections spécifiques de données pour résoudre des tâches spécifiques comme les problèmes mathématiques, répondre aux questions ou créer du code.
Source : Massimiliano Geraci
Cruciale nuance : Google n’utilise pas les données de clics et requêtes utilisateur pour entraîner Gemini. L’entreprise a considéré le faire, mais n’a pas trouvé que les bénéfices du pré-entraînement sur les données de recherche valaient le coût.
MAGIT est fine-tuné pour « produire des réponses textuelles dans le format désiré pour les AI Overviews. » Il n’y a aucune mention de MAGIT utilisé pour prédire quels liens mettre dans les AI Overviews.
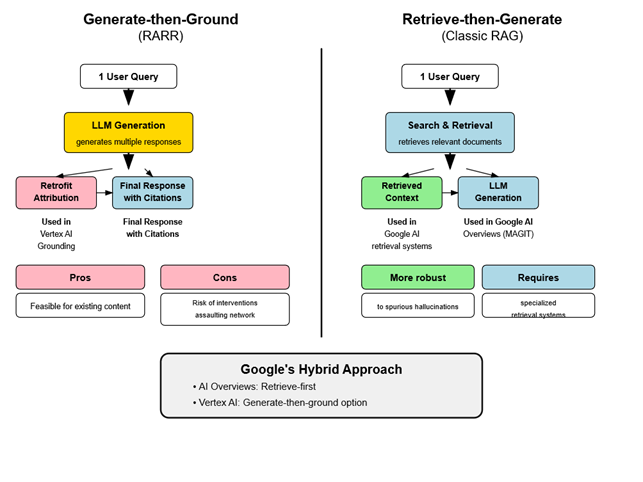
FastSearch : ancrage intelligent pour l’IA
FastSearch représente une innovation fascinante basée sur les signaux RankEmbed. Ce système génère une liste abrégée de sites web classés qu’un modèle de langage peut utiliser pour produire un résultat basé sur les résultats d’une recherche web. FastSearch est plus rapide qu’une recherche web complète, mais moins qualitative.
Concrètement, si vous posez une question sur un événement d’actualité à Gemini, Gemini devrait reconnaître que cet événement n’est pas dans ses données d’entraînement et va s’appuyer sur une recherche dans des pages web pour produire une réponse pertinente. FastSearch serait utilisé pour générer une courte liste de sites web pouvant être utilisés pour constituer la base de la réponse de Gemini.
Source : Massimiliano Geraci
FastSearch est intégré dans Vertex AI Vector search, utilisable via API pour ancrer les réponses LLM sur les résultats Google Search ou même sur des documents propriétaires.
Vision futuriste : le Super Assistant universel
Google ne cache pas ses ambitions. Les documents révèlent : « À plus long terme, les entreprises GenAI s’efforcent de transformer les chatbots en une sorte de ‘Super Assistant.’ Un super assistant serait capable d’aider à accomplir ‘n’importe quelle tâche’ demandée par l’utilisateur. »
Cette vision dépasse largement la recherche web traditionnelle. Google DeepMind vise à construire un modèle du monde permettant de devenir un assistant IA universel, pas seulement pour la recherche internet mais dans le monde réel également. Les projets comme Genie peuvent simuler des environnements du monde réel et entraîner des robots pour des tâches réelles.
L’ère de la recherche textuelle traditionnelle touche peut-être à sa fin. Rechercher « moteur de recherche » ne montre même pas la homepage Google.com dans les résultats, suggérant qu’être un moteur de recherche textuel n’est qu’une étape vers l’objectif ultime de Google : devenir notre assistant quotidien super utile pour tout ce dont nous avons besoin dans la vie.
Implications pour le SEO
Ces nouvelles informations redéfinissent les priorités SEO fondamentales.
Améliorer son contenu et son site pour obtenir un engagement des utilisateurs authentique devient primordial.
La qualité intrinsèque du contenu s’impose comme le facteur différenciant majeur, les algorithmes actuels excellant à détecter la valeur réelle apportée aux utilisateurs.
La préparation à l’écosystème IA devient urgente. Les AI Overviews et futures fonctionnalités d’assistance nécessitent des approches de contenu adaptées : structuration sémantique claire, autorité thématique établie, compatibilité avec les systèmes d’ancrage IA.
La surveillance des métriques de crawl dans Google Search Console devient un indicateur de santé SEO crucial. Un crawl fréquent pour découvrir du nouveau contenu signale une performance positive, tandis qu’une diminution peut indiquer un besoin d’amélioration qualitative.
Enfin, l’abandon progressif de l’obsession du PageRank traditionnel s’impose. L’accent doit se porter sur l’optimisation de l’expérience utilisateur globale et la création de contenu que les utilisateurs trouvent réellement utile, les signaux indépendants des requêtes perdant en importance avec le temps.
Bibliographie et ressources complémentaires
Documents officiels :
Recherches académiques :
- The Anatomy of a Large-Scale Hypertextual Web Search Engine – Brin & Page (pour le Doc ID)
- BERT: Pre-training of Deep Bidirectional Transformers
Analyses expertes :
- Marie Haynes : Analyse Navboost et engagement utilisateur
- Google I/O 2025 : Nouvelle ère de la recherche
- Neper : Justice Leaks – Révélations antérieures du procès Google
- https://www.linkedin.com/pulse/deconstructing-googles-ai-search-insights-from-antitrust-geraci-ezf7c/
- Documentation Google : Créer du contenu utile
Ressources techniques :