

Les fichiers LLMs.txt sont un « standard » proposé dans le cadre d’une initiative personnelle de Jeremy Howard de Response AI pour faciliter le travail de parsing les modèles LLMs de sites qui sont difficiles à crawler.
Je vous invite à relire cet article dans lequel nous présentions ce qu’étaient ces fichiers.
Les porte paroles de Google répètent à l’envi que les fichiers llms.txt ne servent à rien. John Mueller en particulier a récemment déclaré sur BlueSky :
A l’heure actuelle, c’est vrai qu’aucun grand éditeur ne soutient officiellement l’initiative. Et John Mueller affirme que ce fichier ne sert à rien, essentiellement parce que quand il regarde les logs de ses sites, il ne voit pas de bots IA qui viennent aspirer les LLMs.txt
Le bot de ChatGPT explorerait les LLMs.txt
La position un peu extrême de John Mueller se cogne sur quelques faits, qui comme on le sait, sont souvent têtus. Il existe un fournisseur de solutions à base de LLMs, Anthropic, qui a clairement déclaré son intérêt pour l’initiative. Ils ont développé avec Mintlify le deuxième format de fichier, le LLMs-full.txt, qui a par la suite intégré le standard officiel.
Google et Bing n’ont clairement pas besoin de LLMs.txt pour crawler le web correctement, donc il est clair que cette iniative ne peut servir qu’aux autres outils d’IA génératives qui n’ont pas la même infrastructure.
S’agissant d’OpenAI, la société Profound a publié des conclusions selon lesquelles le bot de ChatGPT visitait bien le LLMs.txt, et encore plus souvent la version « full ».
https://mintlify.com/blog/how-often-do-llms-visit-llms-txt
Même chose du côté de Ray Martinez, qui a publié ses logs sur X
A titre personnel, je n’ai qu’un seul site qui possède un LLMs.txt, et les logs ne montrent aucune activité d’OAI-Searchbot. Mais la seule conclusion que l’on peut en tirer c’est que SearchGPT ne le fait pas pour tous les sites, et/ou n’a pas eu l’occasion d’aller chercher le contenu de ce site encore.
Cela prouve aussi, si c’était utile, qu’il ne faut pas faire confiance à des gens qui travaillent chez Google pour expliquer ce que les gens d’OpenAI font ou ne font pas.
Gary Illyes et John Mueller ont par ailleurs une position parfaitement claire sur le sujet : ils ne voient pas l’intérêt du LLMs.txt et cherchent à dissuader l’écosystème web de s’y intéresser.
Mais il s’avère que l’écosystème web fait ce qu’il veut, et l’un des problèmes c’est que l’adoption de ce nouveau standard, si elle est encore faible, n’est pas nulle.
Et du coup, la question de l’indexabilité des fichiers LLMs.txt se pose.
Evitez l’indexation de vos fichiers LLMs par les bots des moteurs de recherche « normaux »
Les fichiers LLMs.txt et LLM-full.txt ne sont pas réellement des doublons de pages existantes. Ils ont des contenus en commun, mais c’est tout.
Donc l’impact de leur indexabilité pour les autres pages du site n’est pas véritablement un problème.
Ce qui ne plait pas au moteur c’est que ce sont des fichiers de type « texte » qui sont donc parfaitement crawlables et indexables par les moteurs, et peuvent donc figurer dans les réponses des moteurs de recherche comme Bing, Google ou Baïdu. Si un lien hypertexte découvrable existe sur le WWW et pointe vers ce fichier, un bot peut l’explorer et l’indexer.
Le problème c’est que leur contenu n’est pas réellement fait pour être lu par les humains et leur présence dans l’index crée une expérience de recherche décevante.
C’est ce qui a forcé John Mueller à concéder sur Bluesky que, oui, il valait mieux bloquer l’indexation de ces fichiers par un « noindex ».
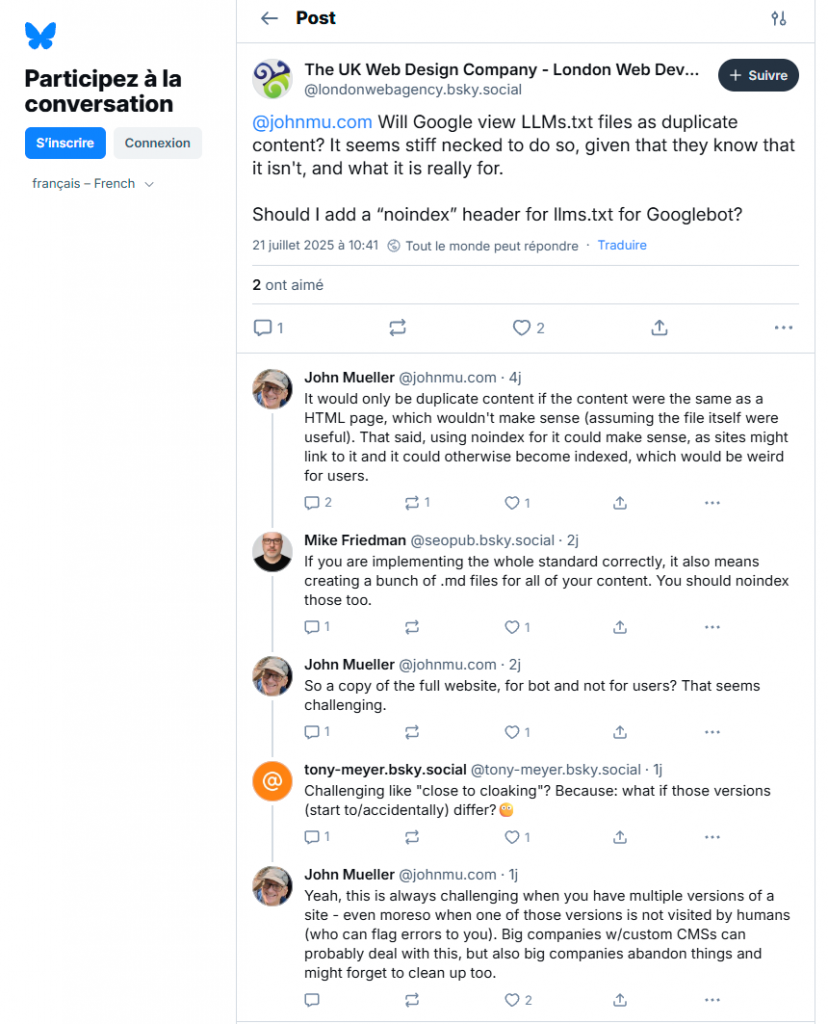
John Mueller n’a pas expliqué exactement comment créer ce header « no index ». Ces fichiers utilisent le format YAML, qui n’est pas un langage de tags, et encore moins du HTML. Donc impossible d’utiliser un attribut dans la balise meta « robots » pour ce genre de cas.
Il faut utiliser une directive X-Robots-Tag dans le header http :
HTTP/1.1 200 OK Date: Tue, 25 May 2010 21:42:43 GMT (…) X-Robots-Tag: googlebot: nofollow X-Robots-Tag: otherbot: noindex, nofollow (…)
Si vous ne savez pas comment utiliser cette balise, voici un article plus détaillé sur le sujet :
Ce qu’il fallait retenir
Aujourd’hui Google ou Bing ne supportent pas le standard LLMs.txt. Et peu d’entreprises de l’IA soutiennent l’initiative officiellement.
En pratique, ces fichiers peuvent être explorés par certains outils d’IA, mais aussi par les bots d’exploration « normaux » comme Googlebot.
Donc Google vous conseille de penser à créer une directive x-robots-tag : noindex pour éviter l’indexation de ces fichiers dans les pages de résultats de Google. Et ceci, moins pour les problèmes de duplicate content que cela génère que pour le très mauvaise expérience de recherche que cela crée pour les utilisateurs.