
Le 1er juillet dernier, Cloudflare a annoncé sur son blog qu’il déployait officiellement un nouveau service : « Pay per Crawl ».
« Pay per Crawl » est tout simplement un paywall que les clients de Cloudflare peuvent activer pour contrôler l’accès à leurs contenus par les différents crawlers.
Si vous souscrivez à ce service, vous pourrez contrôler plus finement quels bots IA vous autorisez, quels bots vous bloquez, et quels bots vous laissez paisser en échange d’une rémunération.
Oui, vous avez bien compris, Cloudflare vous propose de jouer les percepteurs pour vous, et de faire cracher au bassinet les propriétaires de bot IA : Google, Microsoft, Open AI, Apple et tous ceux qui vous bombardent de requêtes pour aspirer votre contenu à des fins que vous approuvez… ou non.
Evidemment, cette initiative voit le jour aujourd’hui parce que beaucoup de propriétaires de sites considèrent que le contrat implicite entre eux et les propriétaires de bots n’est plus équilibré.
En clair, jusqu’à une époque récente, les bots des moteurs de recherche crawlaient vos contenus pour les exploiter pour fabriquer des pages de résultats. Mais en échange, vous receviez du trafic. C’était donnant donnant.
Mais avec les LLMs : ils récupèrent toujours vos contenus, et ne vous envoient du trafic que de manière marginale.
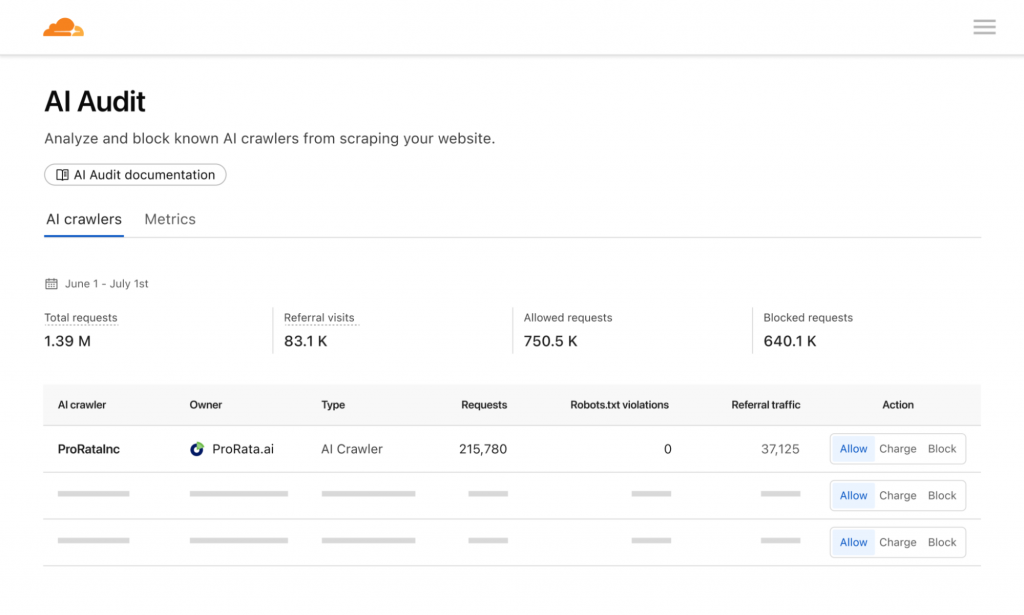
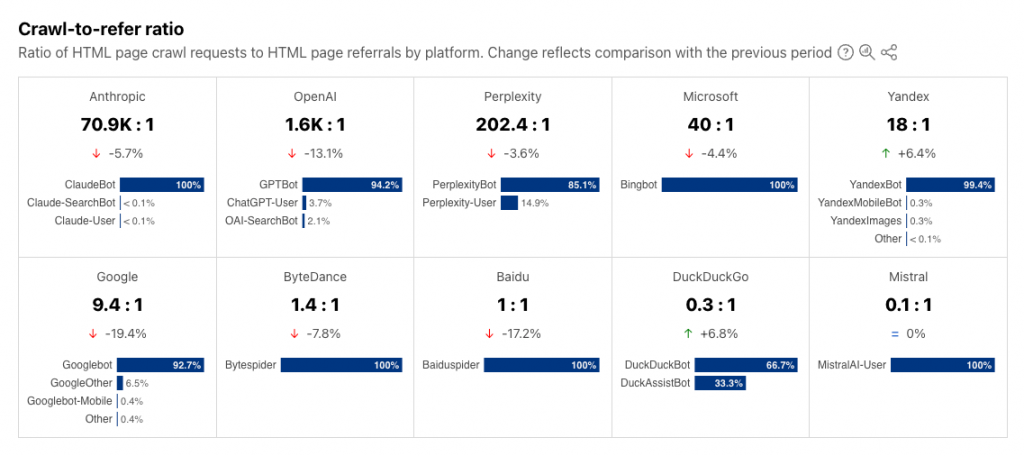
Cloudflare a également révélé en juin que si Google crawlait une page 10 fois plus que le nombre de visites qu’il générait, ce ratio « crawls/referrals » grimpait à 1600 pour ChatGPT et 71000 pour Anthropic.
Concrètement, cela signifie que pour que Claude d’Anthropic génère une visite sur une page de votre site (et donc un HIT sur votre serveur), il va générer 73000 HITS pour explorer votre contenu. En clair, le coût du crawl par les bots IA est devenu disproportionné.
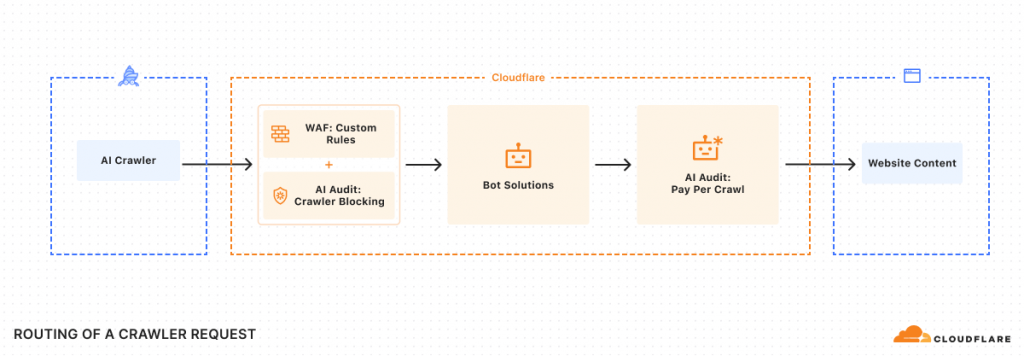
Techniquement, Cloudflare a (presque) tout prévu.
« Pay per Crawl » est encore en « bêta test », mais fonctionne déjà.
Laisser passer un crawler ou le bloquer était déjà une fonctionnalité disponible dans certaines versions de Cloudflare.
Pour ce service, ils ont ajouté une solution technique pour identifier à coup sûr les bots que vous voulez faire payer. Sans cela, il serait facile à un bot bloqué de se faire passer pour un bot ayant un accès gratuit.
Cloudflare propose donc de passer par son protocole « Web Bot Auth », qui prévoit un échange de clés cryptés pour authentifier l’identité des crawlers autorisés à explorer vos pages.
C’est déjà un premier écueil, car qui, dans les acteurs majeurs, va obéir à cette contrainte imposée par Cloudflare dans son coin ?
Le code 402 remis au goût du jour
Si un bot appelle une page, et qu’il doit payer son écot pour la télécharger, il se prendra un code 402 « Payment Required » en retour dans le header, accompagné du prix à payer (non, cet article n’a pas été rédigé un premier avril).

Ce code était bien prévu dans la liste des codes http réservés, mais (à ma connaissance) n’a jamais été utilisé jusqu’ici. Donc aucun bot sur Terre n’a été programmé pour identifier ce code et savoir quoi faire.
Ce qu’attend Cloudflare dans ce cas, c’est que le bot réponde par un header :
GET /example.html crawler-exact-price: USD XX.XXSi les prix correspondent, le contenu pourra être téléchargé, et l’entreprise propriétaire du bot sera facturée.
Mais en pratique, c’est inutilisable
Il y’a trois obstacles non résolus aujourd’hui, et qui empêchent cette solution d’être adoptée par un grand nombre de clients de CloudFlare
- Identifier les bots IA c’est bien en théorie, avec ou sans Web Bot Auth ». Mais l’exploration pour Gemini de Google ou Copilot de Microsoft est faite dans les deux cas par le même bot que pour le moteur de recherche : Googlebot et Binbgbot. Donc impossible de bloquer l’exploration pour les fonctionnalités IA sans bloquer l’exploration des contenus dans le moteur. Donc utiliser cette possibilité pour Bing et Google signifie perdre son trafic organique. Impensable
- Pour les autres bots IA, c’est moins problématique. Mais qui est prêt à payer ? Aujourd’hui personne
- Le système proposé peut fonctionner mais pas sans reprogrammer les schedulers entièrement
Cloudflare s’érige en chevalier blanc du web
On l’a compris, cette initiative de Cloudflare est plus un coup de comm’ et un pavé dans la mare qu’une fonctionnalité qui fonctionnera demain matin.
Cloudflare annonce que certains de ces clients ont déjà souscrit à cette bêta : on peut citer ADWEEK, Atlas Obscura, BuzzFeed, Inc., Fortune, Stack Overflow, News/Media Alliance, The Atlantic, Battelle Media, Evolve Media, Hyperscience, IAB Tech Lab, O’Reilly Media, Quora, Raptive, Sovrn, Inc., StockTwits, Third Door Media, TIME, ou Webflow.
Pour le moment, moins de 20% du trafic web transite par des serveurs de Cloudflare. C’est objectivement énorme, mais Cloudflare n’occupe pas une position dominante qui lui permet d’imposer ses 4 vérités, notamment aux GAFAMs.
Pour que ce système connaisse un minimum d’adoption, il faudrait que d’autres fournisseurs de CDN comme Akamai leur emboîte le pas. Ce qui n’est pas dans leur feuille de route pour le moment.
Mais l’initative de Cloudflare a deux mérites :
- elle fait prendre conscience à l’écosystème des limites du fonctionnement actuel : le « tout gratuit » n’a pas forcément de sens
- elle propose des solutions techniques pour créer des modèles économiques plus respectueux des intérêts des producteurs de contenus, mais aussi ceux des opérateurs d’infrastructure comme les CDN
Ce qu’il faut retenir
Cloudflare a lancé le 1er juillet son service « Pay per Crawl ». Il fonctionne comme une marketplace, mais pour le moment, seuls des producteurs de contenus sont inscrits, et toujours pas de propriétaires de bots.
Toutes les conditions ne sont pas réunies pour que cette initiative prenne, et soit reprise par d’autres acteurs. Mais elle aura peut-être le mérite de faire bouger les choses, car le déséquilibre entre des outils IA qui exploitent des contenus sans rémunérer leurs auteurs crée un problème majeur dans l’économie du web entier.
Avertissement : les bots IA étant désormais bloqués par défaut dans Cloudflare, vérifiez bien les paramètres de Cloudflare si vous tenez à être présents au sein des LLMs. Pour les anciens clients, en principe le crawl reste ouvert, pour les nouveaux, c’est bloqué par défaut.
Pour en savoir plus :
Le billet de blog de Cloudflare :
https://www.seroundtable.com/cloudflare-block-google-ai-overviews-39718.html