

En dix ans, le poids médian d’une page mobile a triplé. Dans le même temps, Google a clarifié que Googlebot ne traite que les 2 premiers mégaoctets du HTML d’une page. Ces deux réalités, documentées par le Web Almanac 2025 et confirmées par les ingénieurs de Google eux-mêmes dans le podcast Search Off the Record, dessinent un problème concret pour les éditeurs de sites.
Voici ce qu’il faut en retenir, et surtout ce qu’il faut vérifier sur vos pages.
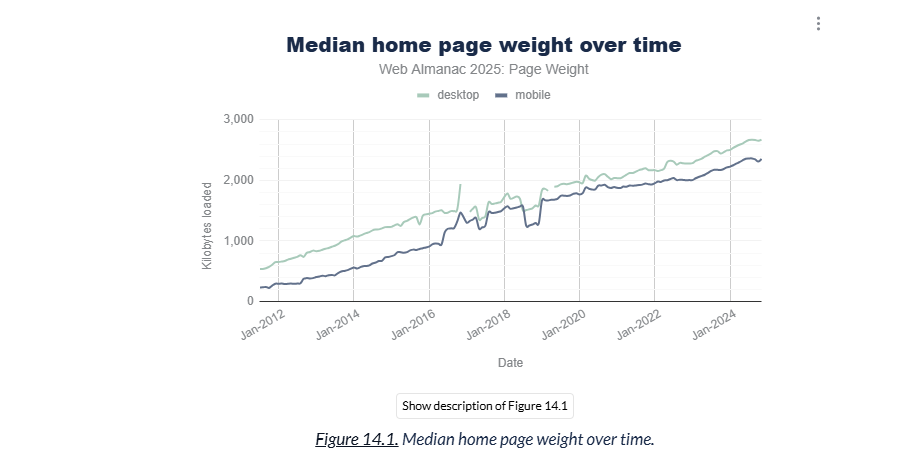
Des pages trois fois plus lourdes qu’en 2015
Le Web Almanac 2025, publié par le HTTP Archive à partir de l’analyse de 17,2 millions de sites, pose un constat sans ambiguïté. En juillet 2015, la page d’accueil mobile médiane pesait 845 Ko. En juillet 2025, elle atteint 2 362 Ko, soit 2,3 Mo. C’est une augmentation de 203 % en dix ans. Sur desktop, la médiane est à 2,86 Mo.
La ventilation par type de ressource éclaire l’origine de ce gonflement. Pour une page d’accueil desktop médiane en 2025 :
- Images : 1 059 Ko (le poste le plus lourd)
- JavaScript : 697 Ko
- Polices (fonts) : 139 Ko
- CSS : 82 Ko
- HTML : 22 Ko
Le JavaScript a doublé en neuf ans (environ 300 Ko en 2015). Les images restent le premier facteur de poids, mais le JS représente désormais le type de ressource le plus fréquemment requêté : 24 fichiers JS en médiane sur desktop, contre 18 images.
La croissance n’est pas linéaire : elle s’accélère. Le poids médian mobile a progressé de 8,4 % entre 2024 et 2025. Au 90e percentile, les pages dépassent les 10 Mo sur desktop.
Ce que Gary Illyes et Martin Splitt en disent
L’épisode 106 du podcast Search Off the Record (Google Search Central, mars 2026) est entièrement consacré à cette question du page weight (poids de page, c’est-à-dire la quantité totale de données qu’un utilisateur doit télécharger pour afficher une page). Gary Illyes et Martin Splitt, tous deux membres de l’équipe Search Relations de Google, commencent par pointer un problème de définition : personne ne s’accorde sur ce que « taille d’une page » signifie exactement.

Pour en savoir plus : l’épisode du podcast « Search Off the Record » sur ce thème
Martin Splitt distingue au moins trois acceptions :
- La taille du HTML brut (les octets du document principal)
- La taille transférée sur le réseau (après compression Gzip ou Brotli)
- La taille totale sur disque (HTML + CSS + JS + images + fonts + vidéo)
Le Web Almanac utilise la notion de page weight qu’il définit comme le volume total de données qu’un utilisateur doit télécharger. Mais Gary Illyes rappelle que pour Google Search, c’est la taille par URL individuelle qui compte. Chaque ressource (le HTML, chaque fichier CSS, chaque fichier JS) est récupérée séparément et soumise à sa propre limite de taille.
Gary précise un point important : la question du poids n’a de sens qu’au niveau de la page individuelle, pas du site entier. Un site peut contenir des milliers de pages légères et quelques pages très lourdes : c’est le poids de chaque page qui détermine l’expérience utilisateur et le comportement du crawler.
La limite Googlebot : 2 Mo pour le HTML, pas 15
C’est l’un des sujets les plus discutés dans la communauté SEO depuis février 2026. Google a mis à jour sa documentation technique pour clarifier les limites de taille de fichier appliquées par ses différents robots d’exploration.
La structure est la suivante :
- 15 Mo : limite par défaut de l’infrastructure de crawl générale de Google (tous les robots confondus). Tout robot qui ne spécifie pas sa propre configuration hérite de cette limite.
- 2 Mo : limite spécifique à Googlebot pour le HTML et les fichiers texte, lorsqu’il crawle pour Google Search. Chaque ressource référencée dans le HTML (CSS, JS) est récupérée séparément, avec sa propre limite de 2 Mo.
- 64 Mo : limite pour les fichiers PDF.
Dans le podcast, Gary Illyes mentionne la limite de 15 Mo comme seuil par défaut de l’infrastructure, tout en expliquant que chaque projet interne à Google peut l’ajuster. Il donne l’exemple des PDF (64 Mo) et précise que les équipes internes modifient régulièrement ces paramètres selon les besoins du produit.
Le billet de blog publié par Google Search Central en mars 2026, intitulé « Inside Googlebot: demystifying crawling, fetching, and the bytes we process », confirme le fonctionnement : lorsque Googlebot atteint la limite de 2 Mo, il interrompt le téléchargement et transmet uniquement la portion déjà récupérée au WRS (Web Rendering Service, le service qui exécute le JavaScript et interprète le rendu de la page). Tout ce qui se trouve au-delà de la coupure est invisible pour l’indexation.
John Mueller a précisé sur Bluesky que 2 Mo de HTML représentent environ 2 millions de caractères, soit l’équivalent d’un roman de 400 pages. La très grande majorité des sites n’atteindra jamais cette limite : la médiane du HTML seul est de 22 Ko sur mobile. Mais certains cas existent.
Les vrais facteurs de « bloat HTML«
Si la médiane HTML est à 22 Ko, qui risque de dépasser les 2 Mo ? Le podcast et les données du Web Almanac identifient plusieurs responsables.
Les images encodées en base64.
Martin Splitt évoque des cas où des développeurs intègrent des images directement dans le HTML sous forme de chaînes de caractères base64 (une technique appelée data URI, qui consiste à convertir un fichier binaire en texte pour l’embarquer dans le code source). L’objectif affiché est d’économiser une requête réseau. Le résultat : des fichiers HTML de 50 Mo dans les cas extrêmes qu’il a observés.
Le structured data empilé.
Gary Illyes exprime un désaccord de longue date avec l’accumulation de données structurées (structured data, c’est-à-dire du balisage au format JSON-LD ou microdata ajouté au code source pour permettre aux moteurs de recherche de mieux comprendre le contenu). Il rappelle que Sergey Brin, cofondateur de Google, estimait à l’origine que les machines devaient pouvoir comprendre le contenu sans balisage supplémentaire. Pourtant, la documentation Google liste aujourd’hui des dizaines de types de structured data supportés. Chaque type ajouté gonfle le HTML avec du contenu qui n’est jamais affiché à l’utilisateur.
Les métadonnées réglementaires et tierces.
Martin Splitt souligne que certaines pages embarquent du markup imposé par des obligations légales, des outils analytiques ou des services tiers. Ce balisage est utile, mais pas pour l’utilisateur final. Il contribue néanmoins au poids brut du document HTML.
Les frameworks JavaScript en SSR.
Les applications en Server-Side Rendering (SSR, technique où le serveur génère le HTML complet de la page avant de l’envoyer au navigateur, au lieu de laisser le JavaScript construire la page côté client) peuvent produire des documents HTML très volumineux, incluant l’état initial de l’application sérialisé dans le code source.
Un vrai risque d’indexation partielle silencieuse
Les tests menés par Spotibo en février 2026 apportent une démonstration pratique du problème. L’équipe a soumis à Google des fichiers HTML de différentes tailles et observé le comportement d’indexation.
Le résultat principal : un fichier HTML de 3 Mo a été tronqué silencieusement à la marque des 2 Mo. Le code source indexé s’interrompt au milieu d’un mot, sans avertissement dans la Google Search Console (GSC). L’outil d’inspection d’URL affiche un statut normal (« URL is on Google », « Page is indexed ») alors que le contenu au-delà de 2 Mo a été ignoré.
Un point technique important : l’outil d’inspection d’URL dans GSC n’utilise pas Googlebot mais un robot distinct (Google-InspectionTool) qui opère sous la limite générale de 15 Mo. Il ne reproduit donc pas la troncature que Googlebot applique réellement lors de l’indexation.
Les conséquences potentielles si du contenu important se trouve au-delà de la coupure :
- Perte de liens internes placés en bas de page
- Perte de données structurées (JSON-LD) insérées en fin de document
- Perte de contenu textuel utile au positionnement
- Perte de balises hreflang (balises indiquant aux moteurs les versions linguistiques alternatives d’une page) pour les sites multilingues
Ce qui compte vraiment : vitesse, UX et conversions
Au-delà du crawl, le podcast rappelle que le poids des pages affecte directement l’expérience utilisateur. Martin Splitt formule une hypothèse : la croissance du poids des pages a dépassé la croissance des débits de connexion mobile ces dernières années.
Gary Illyes reconnaît qu’avec sa connexion fibre 10 Gbit/s en Suisse, il ne ressent pas la douleur. Mais il admet vivre dans une bulle. Lors de ses déplacements dans des pays à infrastructure réseau moins développée, les antennes affichent la 5G mais délivrent un débit proche de la 3G. Martin Splitt évoque un séjour en Antarctique où il disposait de 100 Mo de données satellite pour 20 dollars, un budget dans lequel la seule spécification HTML (14 Mo en version page unique) consommerait 15 % de l’enveloppe.
Les données Google (Think with Google) confirment le lien entre vitesse et résultats business : les sites plus rapides affichent de meilleurs taux de rétention et de conversion. Le poids est un facteur direct de la vitesse, car il détermine à la fois le temps de transfert réseau et le temps de traitement par le processeur de l’appareil.
Le LCP (Largest Contentful Paint, métrique des Core Web Vitals qui mesure le temps d’affichage du plus grand élément visible dans la fenêtre du navigateur) est directement corrélé au poids total de la page. Les pages au 90e percentile (plus de 10 Mo) affichent un LCP médian supérieur à 4 secondes, bien au-delà du seuil « bon » de 2,5 secondes fixé par Google.
Recommandations : ce qu’il faut vérifier et corriger
Google, via le billet de blog de mars 2026, fournit des conseils concrets pour les éditeurs de sites. Ces recommandations sont cohérentes avec ce que Gary et Martin exposent dans le podcast.
Auditer la taille HTML brute de vos pages. Ouvrez les DevTools du navigateur (F12), onglet Network, rechargez la page et filtrez par « Doc ». La colonne « Size » montre la taille transférée (compressée) et la colonne « Content » la taille décompressée. C’est cette dernière valeur qui compte pour la limite Googlebot.
Placer le contenu critique en haut du document HTML. Les balises meta, le title, les liens canoniques, le hreflang et les données structurées essentielles doivent apparaitre le plus tôt possible dans le code source. Si une troncature se produit, ces éléments seront préservés.
Externaliser CSS et JavaScript. Déplacer les styles et scripts dans des fichiers externes réduit le poids du document HTML principal. Chaque fichier externe est récupéré séparément par Googlebot avec sa propre limite de 2 Mo.
Ne jamais encoder d’images en base64 dans le HTML. Cette pratique, censée économiser une requête réseau, gonfle considérablement le document. Utilisez des balises <img> classiques avec des URLs vers des fichiers images optimisés.
Dimensionner le structured data au nécessaire. N’ajoutez que les types de données structurées qui apportent un bénéfice mesurable (éligibilité à un résultat enrichi). Testez avec le Rich Results Test de Google. Privilégiez le format JSON-LD en bloc <script> placé dans le <head>.
Optimiser les images. Google utilise en interne un linter qui bloque la publication d’images de plus de 1 Mo sur son propre site de documentation Search Central, comme Gary Illyes le révèle dans l’épisode. Utilisez les formats modernes (WebP ou AVIF, qui offrent une réduction de 25 à 50 % par rapport au JPEG) et le lazy loading natif (attribut loading="lazy" sur les balises <img>, qui diffère le chargement des images hors de la zone visible).
Activer la compression au niveau du transport. La compression Brotli (algorithme de compression développé par Google, plus efficace que Gzip pour les contenus web) réduit la taille des données transférées sur le réseau. Cela n’affecte pas la taille décompressée mesurée par Googlebot, mais améliore le temps de chargement pour les utilisateurs.
Utiliser les images responsives. L’attribut srcset sur les balises <img> permet de servir des images adaptées à la taille de l’écran. Gary mentionne qu’il envoyait autrefois des images de 59 mégapixels à des smartphones, une pratique que Martin qualifie de courante et qu’il cherche lui-même à corriger sur son nouveau site.
Bibliographie
- Web Almanac 2025, chapitre Page Weight (HTTP Archive, janvier 2026)
- Inside Googlebot: demystifying crawling, fetching, and the bytes we process (Google Search Central Blog, mars 2026)
- Search Off the Record, épisode 106 (Google Search Central, mars 2026)
- We Tested Google’s New 2MB Crawl Limit. What happens? (Spotibo, février 2026)
- Googlebot File Limit Is 15MB, 2MB & 64MB For PDF (Search Engine Roundtable, février 2026)
- What Googlebot’s 2MB Crawl Size Limit Means For SEO (DebugBear, février 2026)
- Page bloat update: How does ever-increasing page size affect your business? (SpeedCurve, 2025)
- How page speed helps with conversions (Think with Google)