

Votre contenu SEO tient peut-être à un seul appel API
Les architectures web modernes reposent massivement sur des APIs JSON (interfaces de programmation qui renvoient des données structurées au format JavaScript Object Notation). Fiches produit, avis clients, prix en temps réel, descriptions dynamiques : sur de nombreux sites, le contenu visible par l’utilisateur n’existe pas dans le HTML initial. Il est injecté après coup par du JavaScript qui interroge une ou plusieurs APIs, parfois hébergées par des prestataires tiers.
Ce fonctionnement pose un problème structurel pour le référencement naturel. Googlebot, le robot d’exploration de Google, ne voit pas votre page comme un navigateur classique. Il opère en deux temps : d’abord un crawl du HTML brut, puis un rendu via le Web Rendering Service (WRS), un navigateur Chromium headless qui exécute le JavaScript. C’est durant cette seconde phase que les appels API sont déclenchés. Si l’API externe est lente, indisponible ou en erreur à cet instant précis, le contenu qu’elle devait fournir n’apparaît tout simplement pas dans le DOM rendu.
Le résultat : Google indexe une version incomplète de votre page, parfois dépourvue de son contenu principal. Et comme le moment du rendu est imprévisible (il peut survenir des heures, voire des jours après le crawl initial), l’indisponibilité passagère d’une API a des effets disproportionnés sur la visibilité organique.
Comment Google rend vos pages : un pipeline en trois étapes
Pour comprendre la vulnérabilité, il faut détailler le fonctionnement du pipeline d’indexation de Google, documenté par l’équipe Search Central et explicité par Martin Splitt, Developer Advocate chez Google.
Première étape : le crawl. Googlebot envoie une requête HTTP et récupère le HTML brut de la page. À ce stade, aucun JavaScript n’est exécuté. Les liens présents dans le HTML sont extraits et ajoutés à la file d’attente de crawl. Si votre contenu principal n’est pas dans ce HTML initial, il est invisible à cette étape.
Deuxième étape : le rendu. La page est placée dans la file d’attente du WRS. Google a indiqué que le délai médian entre crawl et rendu est de 5 secondes, mais ce chiffre masque une réalité plus contrastée. Pour le 90e percentile des sites, ce délai peut se compter en minutes. Et les recherches menées par Onely montrent que 5 à 50 % des pages nouvellement ajoutées conservent des éléments JavaScript non indexés deux semaines après leur soumission au sitemap.
Troisième étape : l’indexation. Google analyse le DOM rendu et décide d’intégrer ou non la page à son index. Si le rendu a échoué partiellement (API en timeout, ressource bloquée), c’est la version incomplète qui est évaluée.
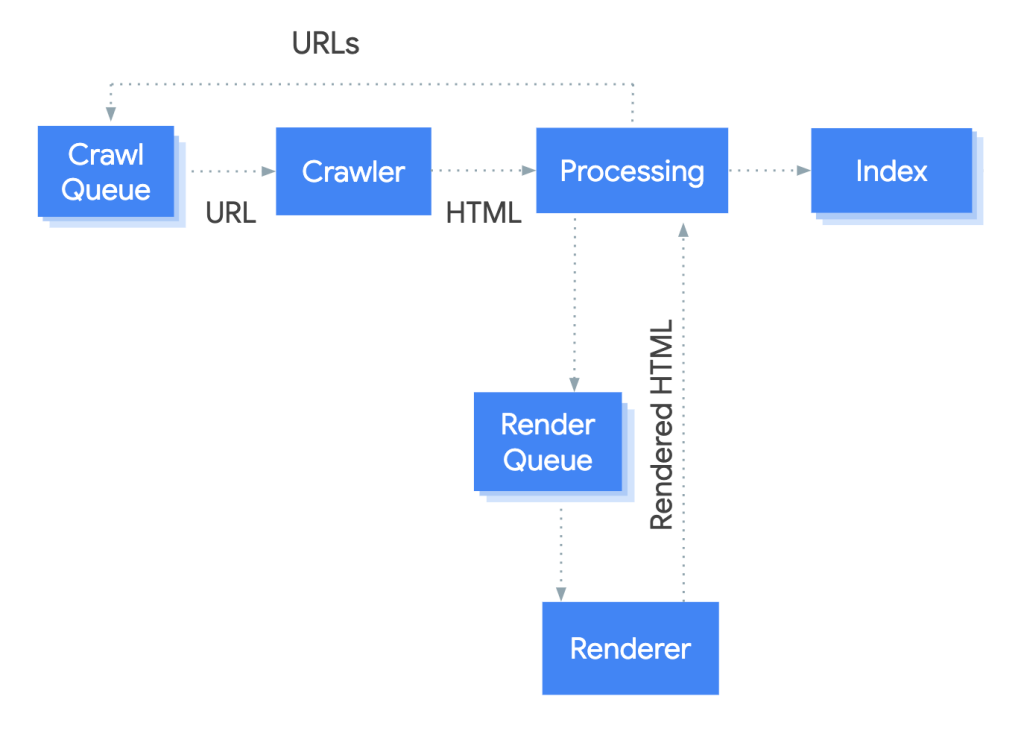
Ce qui se passe concrètement quand l’API échoue
Lors de la phase de rendu, le WRS exécute le JavaScript de la page comme le ferait un navigateur. Si le code contient un appel fetch() vers une API externe et que cette API renvoie une erreur (500, 503, timeout réseau), plusieurs scénarios se produisent.
Indexation partielle. Googlebot indexe ce qu’il voit, c’est-à-dire le HTML initial augmenté du DOM partiellement rendu. Les sections dont le contenu dépendait de l’API absente apparaissent vides ou avec un état de chargement (spinner, placeholder). Sur un site e-commerce, cela peut signifier des fiches produit sans prix, sans description, sans avis, donc un contenu perçu comme thin content (contenu pauvre) par les algorithmes de qualité.
Disparition intermittente. Chaque crawl est indépendant. Si votre API fonctionne 95 % du temps mais tombe à chaque pic de charge ou maintenance planifiée, il suffit que le WRS passe au mauvais moment pour que Google enregistre une version dégradée. Ce phénomène est particulièrement insidieux car il ne se reproduit pas de manière prévisible.
Réduction de la fréquence de crawl. Si l’API génère des erreurs 5xx côté serveur, Googlebot interprète ces erreurs comme un signal de surcharge. Il ralentit alors sa fréquence de visite sur l’ensemble du hostname concerné, retardant la découverte et la mise à jour de toutes les pages du site.
Le crawl budget, victime silencieuse des appels API
Le crawl budget désigne le nombre d’URL que Googlebot peut et veut explorer sur un site dans un laps de temps donné. Il est déterminé par deux facteurs : la capacité de crawl (ce que le serveur peut supporter) et la demande de crawl (l’intérêt de Google pour le contenu).
Or, les requêtes API consomment directement ce budget. Lors du rendu, chaque appel fetch() vers un endpoint JSON constitue une requête HTTP supplémentaire que le WRS doit effectuer. Google a documenté ce mécanisme dans son article « Crawling December » : le crawl des ressources nécessaires au rendu d’une page entame le budget du hostname qui héberge la ressource.
Le WRS met en cache les fichiers JavaScript et CSS pendant 30 jours maximum pour limiter cet impact. Mais les réponses d’API sont par nature dynamiques : elles changent à chaque requête, contiennent souvent des timestamps, des identifiants de session ou des données personnalisées. John Mueller a souligné lors d’un SEO Office Hours qu’il peut être difficile pour Google de cacher les résultats d’API, ce qui entraîne un volume élevé de requêtes vers ces endpoints.
Un cas documenté par le consultant Ziggy Shtrosberg illustre l’ampleur du problème : sur un site client, le rapport Crawl Stats de la Search Console révélait que Googlebot consacrait 58 % de son temps de crawl à des requêtes JSON issues d’un composant de recherche produit.
Le faux sentiment de sécurité du navigateur
Un piège fréquent pour les équipes techniques : tester le site dans un navigateur et constater que tout fonctionne. Mais le contexte d’exécution de Googlebot diffère radicalement de celui d’un utilisateur.
Pas de session ni de cookies. Le WRS ne conserve pas de session entre les rendus. Si votre API requiert une authentification par cookie ou un token de session, l’appel échouera silencieusement pour Googlebot.
Pas de retry automatique. Un navigateur moderne peut relancer une requête échouée via un service worker ou une logique de retry côté client. Le WRS n’exécute pas les service workers et ne bénéficie pas de ces mécanismes de résilience.
Pas de timeout fixe, mais des limites réelles. John Mueller a précisé qu’il n’existe pas de timeout fixe pour le rendu, car le temps varie selon les ressources en cache. Cependant, les praticiens SEO observent qu’au-delà de 5 secondes d’exécution JavaScript, le risque de rendu incomplet augmente significativement. Les tests réalisés par des outils comme Screaming Frog confirment que les pages dont les temps de réponse dépassent 5 secondes présentent souvent des problèmes de rendu.
Un cache de ressources décalé. Le WRS utilise un « service wrapper » qui peut servir des versions cachées de fichiers JavaScript datant de plusieurs semaines, comme l’a expliqué Martin Splitt. Le rendu peut donc s’appuyer sur une version obsolète de votre code, qui appelle un endpoint API ayant changé entre-temps.
Auditer sa dépendance : les signaux d’alerte
Avant qu’un incident ne survienne, plusieurs indicateurs permettent d’évaluer l’exposition d’un site à ce risque.
Dans Google Search Console. Le rapport Crawl Stats (accessible via Paramètres) détaille les types de fichiers crawlés par Googlebot. Une proportion élevée de requêtes JSON dans la section « Par type de fichier » constitue un signal d’alerte. L’outil d’inspection d’URL permet également de comparer le HTML brut et le HTML rendu : si des sections entières de contenu n’apparaissent que dans la version rendue, elles dépendent du JavaScript et potentiellement d’APIs.
Dans les logs serveur. L’analyse des logs permet d’identifier les requêtes du WRS vers vos endpoints API, leur fréquence, leur temps de réponse et leur taux d’erreur. Des outils comme Screaming Frog Log Analyzer, Botify ou OnCrawl facilitent ce travail.
En désactivant JavaScript. Un test simple mais révélateur consiste à consulter vos pages critiques avec JavaScript désactivé dans le navigateur. Tout contenu qui disparaît est un contenu qui dépend du rendu JavaScript, et potentiellement d’un appel API externe. C’est l’approximation la plus directe de ce que Googlebot voit lors de la phase initiale de crawl.
Via l’inspection d’URL en mode « live test ». John Mueller recommande de créer une page de test qui appelle l’API avec une URL volontairement cassée, puis de vérifier le rendu via l’outil d’inspection d’URL de la Search Console. Cette méthode permet de voir exactement ce que Google indexerait en cas de défaillance API.
Les stratégies de mitigation
La solution la plus robuste consiste à éliminer la dépendance au rendu client-side pour le contenu critique destiné à l’indexation.
Server-Side Rendering (SSR). Le rendu côté serveur consiste à exécuter le JavaScript sur le serveur avant d’envoyer le HTML au client (et à Googlebot). L’appel API est effectué côté serveur, et la réponse est intégrée dans le HTML initial. Si l’API échoue, le serveur peut appliquer une logique de fallback (contenu de secours) : servir une version cachée, afficher un contenu par défaut, ou renvoyer un code HTTP approprié. Les frameworks comme Next.js, Nuxt.js ou Angular Universal supportent nativement ce pattern.
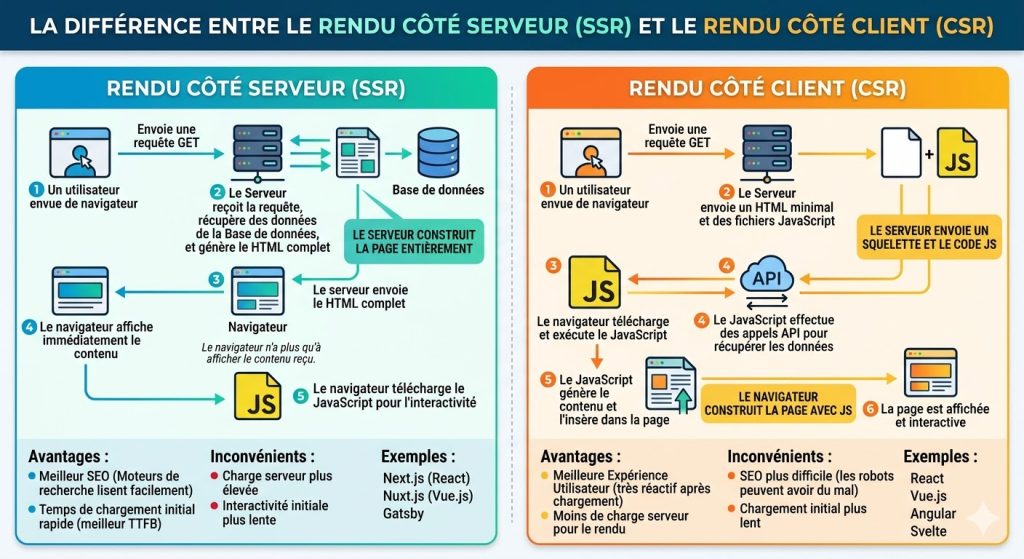
Static Site Generation (SSG). Pour les contenus qui ne changent pas à chaque requête (pages catégories, contenus éditoriaux, landing pages), la génération statique pré-construit les pages au moment du déploiement. L’API est appelée une seule fois au build, et les pages servies sont du HTML pur. C’est la stratégie la plus résiliente.
Cache côté serveur des réponses API. Même en SSR, il est essentiel de cacher les réponses API avec un TTL (Time To Live, durée de validité du cache) adapté. En cas de panne de l’API, le serveur peut servir la dernière réponse en cache plutôt qu’une page vide, pattern connu sous le nom de stale-while-revalidate.
Gestion explicite des erreurs. Le code doit prévoir le cas où l’API ne répond pas : timeout explicite, fallback sur un contenu statique, et surtout un code HTTP cohérent. Servir un 200 avec une page vide est pire qu’un 503 avec un header Retry-After, car Google interprétera la page vide comme du contenu légitime.
Ce que Google cache (et ce qu’il ne cache pas)
Un point technique souvent mal compris concerne le cache du WRS. Google a documenté en décembre 2024 que le WRS met en cache les ressources JavaScript et CSS pour une durée pouvant aller jusqu’à 30 jours, indépendamment des directives HTTP de cache envoyées par le serveur. Ce cache agressif a un double effet.
Côté positif, un fichier JavaScript stable ne sera pas re-téléchargé à chaque rendu, ce qui préserve le crawl budget. Côté négatif, une mise à jour de votre fichier JS pourrait ne pas être prise en compte immédiatement par le WRS. Google recommande d’utiliser le content fingerprinting (inclure un hash du contenu dans le nom du fichier, par exemple app.3f2a9b1c.js) pour forcer le WRS à détecter les changements.
Mais ce mécanisme de cache ne s’applique pas aux réponses API. Les endpoints JSON dynamiques, dont l’URL et le contenu changent à chaque appel, ne bénéficient pas de cette mise en cache. C’est pourquoi John Mueller insiste sur l’importance de rendre les résultats API cachables : éviter les timestamps dans les URL, utiliser des paramètres de requête stables, et permettre au WRS de réutiliser une réponse précédente sans la refetcher systématiquement.
Implications pour les architectures headless et API-first
La tendance aux architectures headless CMS (systèmes de gestion de contenu découplés où le frontend consomme le contenu via API) rend cette problématique plus prégnante. Un site propulsé par un CMS headless comme Strapi, Contentful ou Prismic repose entièrement sur des appels API pour alimenter ses pages.
Dans cette configuration, la moindre interruption du service API affecte potentiellement l’ensemble des pages du site, pas uniquement un composant isolé. La chaîne de dépendances s’allonge : CDN, gateway API, service d’authentification, base de données, chacun de ces maillons peut provoquer une indisponibilité.
Pour ces architectures, le SSR avec fallback n’est pas une option mais une nécessité. Les frameworks modernes (Next.js avec l’App Router, Nuxt 3 avec ses composants serveur) permettent d’implémenter des patterns de streaming SSR : le serveur envoie immédiatement le HTML disponible (navigation, structure de page) puis diffuse progressivement les données au fur et à mesure que les APIs répondent. Si une API ne répond pas dans le délai imparti, le composant concerné affiche son fallback, mais le reste de la page est intact et indexable.
Sources
- JavaScript SEO Basics, Google Search Central
- Crawling December: The how and why of Googlebot crawling, Google Search Central Blog
- Google Removes the Accessibility Section from Its JavaScript SEO Documentation, ALM Corp
- Google’s Rendering Delay is Now 5 Seconds BUT…, Onely
- Are JSON requests wasting your website’s crawl budget?, Ziggy Shtrosberg
- Google: There Is No Fixed Timeout For JavaScript Page Rendering, Search Engine Roundtable
- How Google Deals With Crawl Budget, Lumar SEO Office Hours
- Common JavaScript SEO Issues That Affect AI Content Rendering, INSIDEA
- How Googlebot Works: The Complete Guide, ALM Corp
- SEO debugging: Diagnose & fix crawl, indexing & ranking issues, Search Engine Land