

Vous êtes vous déjà demandé pour quelle raison obscure les IA génératives étaient aussi mauvaises pour « sourcer » l’origine de leurs informations ?
Beaucoup ont soupçonné les pionniers de l’IA générative de vouloir « disrupter » les modèles habituels pour conserver 100% du trafic sur leur site.
D’autres, plus adeptes de la théorie du complot, les ont soupçonné de « cacher » les sources, pour masquer tous les défauts de leurs réponses :
- réemploi de sources non fiables ou sans réelle autorité
- reprise de fake news
- ou présence d’erreurs factuelles dans la réponse, alors que la source contenait la bonne information.
En réalité, la raison de cette incapacité à « sourcer » son information vient d’une raison bien plus profonde. C’est lié à une caractéristique fondamentale des LLMs.
En réalité, un modèle de fondation, ou un Large Language Model, est construit en analysant une masse énorme de documents et de fichiers digitaux, pour élaborer un système qui crée des contenus qui leur ressemblent, mais sans conserver la mémoire exacte de l’emplacement des informations qui ont servi à entraîner le modèle.
Stocker la source ne fait pas du tout partie du processus.
Pourquoi les LLMs « oublient » les urls des sources avec lesquelles ils ont été entrainés?
Si un index de moteur de recherche « classique » est bien conçu pour permettre de retrouver facilement les urls des documents indexés et donnés comme réponse, ce n’est pas du tout le cas avec un LLM.
Pour entrainer un LLM comme GPT 3.5, 4 ou 5, ou Gemini ou Claude, on passe par une phase de « prétraitement » de l’information pour les convertir dans un format que le logiciel va être capable de traiter.
Pour un LLM textuel, les données en entrée doivent être du texte aussi brut que possible. Et un LLM a vocation à apprendre en analysant des types de documents aussi variés que possibles. Donc pour entraîner le modèle, on doit convertir aussi bien le contenu de livres, de pdf, de docs word que des pages webs en des documents doté d’un format compatible entre eux.
Et dès cette phase de prétraitement, le contenu web en particulier est particulièrement « nettoyé ».
Toutes les balises HTML, les liens hypertexte, les meta données, etc… sont retirées pour que le contenu textuel des pages webs puisse être « avalé » par l’outil comme n’importe quel bout de texte.
- le contenu est décomposé en tokens (par exemple « protection du climat », « loi sur le chauffage », « iPhone », « comparaison de prix »)
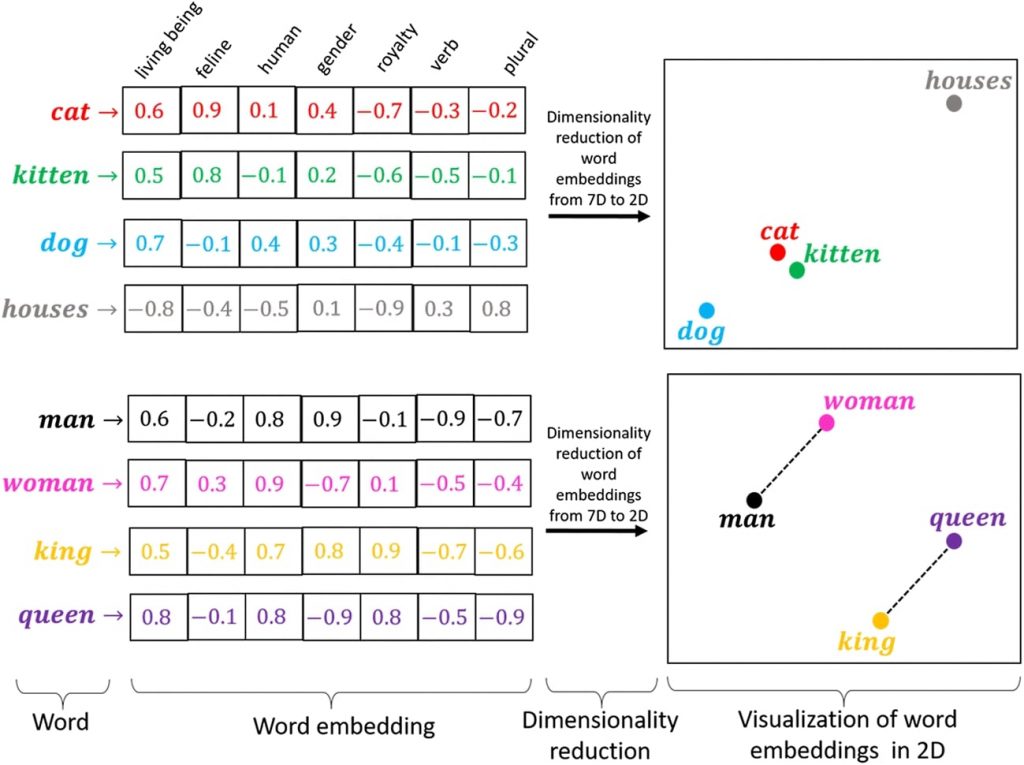
- Ces tokens sont convertis en vecteurs (tableaux mathématiques de nombres comportant jusqu’à des milliers de dimensions). Notez que ces text embeddings comme on appelle ces vecteurs ne contiennent que des nombres associés à des tokens (pas d’urls sources associées)
- Ces vecteurs sont intégrés aux paramètres du modèle – sans texte, structure ou affectation
Un schéma très simplifié du processus de création des vecteurs de text embeddings. Source : documentation de l’outil Keras

Les vecteurs de nombres donnent les coordonnées dans un espace sémantique virtuel. Ici une représentation sur 3 axes seulement (en réalité on est sur des dizaines de milliers de dimensions) . Les « tokens » proches dans cet espace virtuel sont ceux qui sont proches sémantiquement. Les LLMs à base de Transformers comme GPT ou Gemini sont encore plus complexes : chaque terme se voit attribuer des vecteurs différents en fonction du contexte. Le mot « banque » aura un vecteur différent selon qu’il apparaît dans « aller à la banque » ou « au bord de la banque » => on parle d’embeddings contextuels
Lors de cette étape, l’accent est mis sur l’isolation du contenu textuel pur du bruit et des informations superflues présentes dans les données brutes. Les URL, qui fournissent des liens vers les sources originales du texte, sont souvent supprimées lors de ce processus.
Bref, ce nettoyage est indispensable pour que le modèle « apprenne » correctement à générer du contenu correct.
Et le modèle ne mémorise pas du tout la relation « information » <-> « source de l’information.
Par ailleurs, la suppression des urls dans les données d’apprentissage permet aussi de masquer l’origine véritable de ces données. Ce qui s’avère pratique quand on « oublié » de demander l’autorisation à un producteur de contenus d’exploiter ses oeuvres protégées par les droits d’auteur ou les droits voisins (cas purement hypothétique qui ne s’est jamais produit bien entendu).
Est-ce que les modèles pourraient conserver toutes les urls des sources ?
En pratique, le processus d’apprentissage des LLM vise à extraire les informations linguistiques essentielles des données textuelles, sans tenir compte des spécificités des sources individuelles. Cela permet aux modèles de développer une compréhension plus générale de la langue, applicable à différents contextes et domaines.
Cette capacité des modèles de langage de type LLM à être utile dans cas d’usage très variés passe par un focus, lors de leur entrainement, sur une capacité à l’abstraction et la généralisation. Donc même si on trouvait le moyen de conserver les urls dans les données d’entrainement, le processus de fabrication du modèle tendrait à son tour à les faire disparaîtres. En particulier la création de ce que l’on appelle les plongements lexicaux fait disparaître aussi cette notion de source.
Les modèles de type LLM sont par ailleurs, comme leur nom l’indique « Large », c’est à dire très gros. La quantité de paramètres et de données embarquées dans les modèles est déjà énorme, et stocker en plus des sources représente un défi très important.
Sans compter qu’il faudrait « recrawler » régulièrement les sources pour les mettre à jour en fonction de leur évolution, de leur disparition du web etc.
Cet absence de mise à jour en temps réel crée aussi un autre effet de bord : les modèles commencent à régurgiter des informations obsolètes dès que leur entrainement s’est achevé.
Tout cela est un casse tête, et en pratique, tout le monde fait comme Open AI : le modèle ne contient pas toutes les sources.
Je dis bien toutes car sur les très gros modèles, les LLMs contiennent parfois des informations de ce type, mais ce n’est pas systématique et pas fiable. Il est assez fréquent que le LLM donne comme source une page qui ne contient pas l’information restituée. L’outil vous fournit alors juste une source « probable ». Pas une source exacte.
Cela vient du fait que les noms de domaines, comme cdiscount.com, sont traités comme des entités nommées, et les chemins d’urls (/produits/vestes/hommes) comme des schemas linguistiques. Du cout le LLM peut vous proposer une url inventée comme source probable : https://www.cdiscount.com/produits/vestes/hommes (ne cherchez pas, elle n’existe pas)
Comment fait Google avec ses AIO alors ?
Depuis la sortie de ChatGPT, les utilisateurs ont vite fait comprendre aux sociétés qui produisaient des outils d’IA génératives que citer des sources c’est mieux.
Donc les outils ont été complétés par une couche « RAG » (Retrieval Augmented Generation) qui consiste à aller chercher sur le web à la demande des sources d’information qui vont alimenter la réponse en temps réel. Plus de problème d’obsolence de l’information dans le modèle, et plus de problèmes pour citer les sources qui sont celles qui viennent d’être interrogées. C’est ce que l’on voit à l’oeuvre dans SearchGPT ou DeepSeek.
Mais pour Google ou Microsoft, qui ont à leur disposition un index de moteur « classique », c’est encore mieux. La question posée au LLM peut être convertie en requêtes sur le moteur classique, et le contenu de l’index peut-être utilisé pour fabriquer la réponse. On peut même utiliser le mode RAG pour les requêtes sur de l’actualité brûlante en allant crawler les pages en temps réel. Mais pour la majorité des requêtes, l’index à l’ancienne sera largement suffisant pour créer une réponse pertinente, avec en bonus la possibilité de citer les sources exploitées dans l’index.
Conclusion : OpenAI a un gros désavantage par rapport à Bing et Google. Perplexity et OpenAI seront probablement forcés de créer aussi leur propre « index moteur » pour rattraper le retard qu’ils ont sur les principaux moteurs de recherche dans ce domaine.
Quelles conclusions en tirer pour le GEO
Cette caractéristique fondamentale des LLMs a un impact très fort pour le GEO. Pour un LLM classique (Claude, GPT, Mistral, LLama, Gemini), le modèle a été construit en ignorant la notion de page web et de lien hypertexte.
Dans ces outils, les scores d’autorité comme le Pagerank, le Trustrank et tout score calculé à partir du maillage hypertexte perdent toute pertinence.
Les résultats d’un LLM vont être plutôt influencés par la fréquence des mentions (d’une marque, d’une entité etc…).
En clair, tous vos efforts de netlinking, ou de maillage interne, ne servent à rien pour être plus visibles dans ces modèles.
Par contre, dans le mode IA ou les aperçus IA de Google, les scores SEO traditionnels, dont les scores indépendants des requêtes comme le Pagerank et ses autres avatars restent très pertinents et contribuent largement au choix des sources et du contenu de la réponse.
Enfin ce sera comme cela tant que les index traditionnels ne seront pas remplacés par de nouveaux index optimisés pour les IA génératives. Mais c’est un sujet pour plus tard.