

La navigation à facettes est une fonctionnalité de plus en plus répandue sur les sites internet, notamment les sites ecommerce.
Suivant la façon dont elle est implémentée, une navigation à facettes peut-être la pire ou la meilleure des choses en SEO.
Dans cet article, nous allons faire le tour des principaux inconvénients que vous pouvez rencontrer avec cette fonctionnalité, et découvrir comment les éliminer.
Une navigation à facettes ? Qu’est-ce que c’est ?
Lorsque l’on souhaite donner accès à des données sur un site web, on se sert souvent d’une base de données dite « structurée ».
Si on prend le cas d’un catalogue de produits, l’aspect « structuré » prendra la forme d’une table stockant les données d’un produit (libellé produit, image d’illustration, description, prix etc…) mais aussi un certain nombre d’attributs pouvant prendre différentes valeurs.
Parmi les couples « attributs » et « valeurs » classiques on trouvera par exemple :
- Taille = 40
- Couleur = rouge
- Prix < 500 euros
- Date < 2016
- Tag = durable
- etc.
La navigation à facettes (ou recherche à facettes) consiste à permettre à l’utilisateur de pouvoir filtrer facilement les produits du catalogue grâce à une combinaison de couples attributs valeurs. Ce sont ces différents filtres possibles que l’on appelle « facette »
A ne pas faire : une « query string » incompréhensible pour le moteur
Première recommandation avant d’aborder les problèmes posés par la navigation à facettes pour le SEO : attention à la syntaxe de vos urls.
Garder une syntaxe la plus classique possible pour les urls fait partie des consignes répétés par Google depuis des années. Or certaines plateformes e-commerce utilisent des caractères spéciaux « exotiques » pour séparer les attributs et les valeurs, comme des « ! » ou des « | », quand ce n’est pas des « $ » ou des virgules ou des points virgules.
Mais si vous voulez que Google comprenne comment vos filtres sont structurés, il est primordial de réécrire ces urls en quelque chose de plus classiques.
Donc ceci est ok :
https://www.mondomaine.com/category?id_cat=23&marque=adidas&taille=40Mais ceci est ko :
https://www.mondomaine.com/category!id_cat$23|marque$adidas|taille$40§order,,price,decreasingLa première syntaxe permet à Google de comprendre facilement comment chaque page catégorie est filtrée.
Mais pour la seconde, il sera probablement impossible pour le moteur d’en tirer la moindre logique réutilisable.
Le problème de l’explosion combinatoire des urls et des pages avec une navigation à facettes
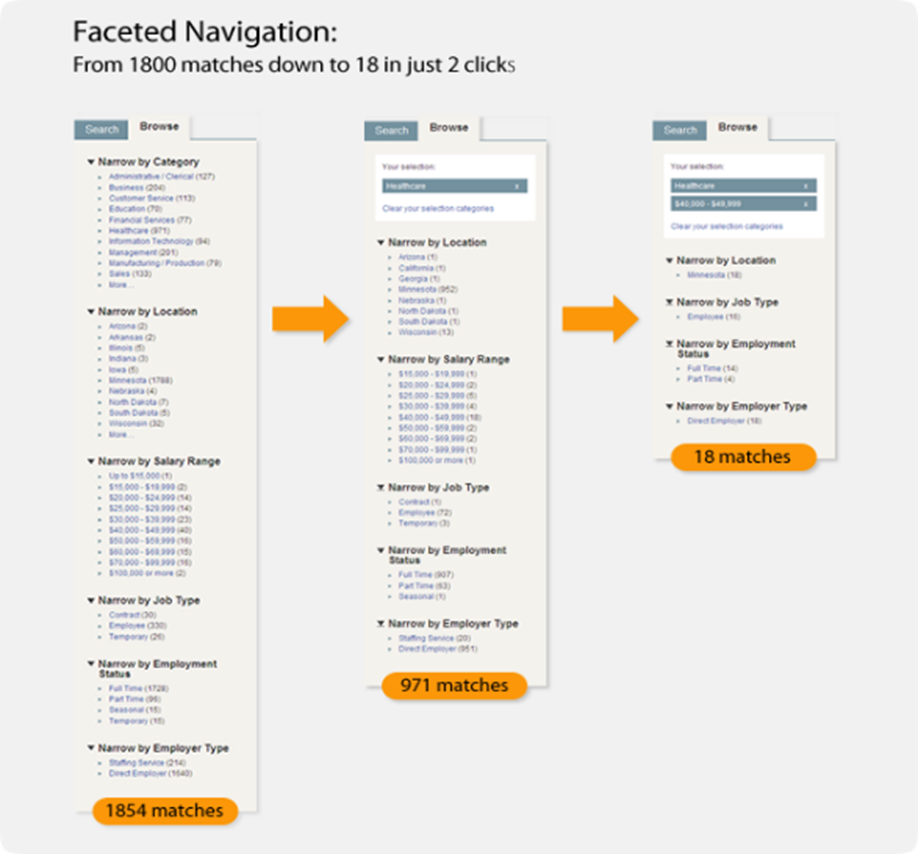
Le principal problème que peut poser la navigation à facettes est l’explosion combinatoire des pages filtrées par facette.
Prenons un site comportant 2000 produits répartis dans 100 catégories…
Classiquement, ce site comportera au départ au maximum 2500 pages, dont 2000 pages produits.
Maintenant, imaginons que ces produits soient des vêtements, disponibles dans 10 tailles, 5 couleurs, 5 matières, et dans 5 segments de prix, et provenant d’une trentaine de marques…
Chaque page de catégorie génère à présent potentiellement :
1 x 10 x 5 x 5 x 5 x 30 = 37500 pages filtrées différentes !
Soit 3 750 000 pages de listings pour tout le site !
Les signaux de qualité désastreux envoyés par toutes ces pages filtrées par facettes
Bon, une fois que vous avez multiplié par 37500 la taille de votre site, qu’est-ce qui peut mal se passer ?
En pratique, bien des choses. Voici quelques conséquences néfastes immédiates de cette situation
- Si Google arrivait sans problème à explorer le petit site de 2500 pages, crawler et indexer 3750000 pages risque d’être au dessus du « crawl budget » qu’il voudra bien consacrer à ce site
- En plus le PR interne des pages listings produits se retrouve divisé par 37500 : autant dire que l’on tombe si bas qu’une partie des pages seront ignorées. Une partie des pages listings ne seront jamais indexées. Et même si elles sont indexées, elles n’auront plus aucune chance de lutter contre les pages listing produits de vos concurrents.
- La plupart des pages filtrées seront des doublons ou des quasi doublons
- beaucoup de combinaisons de filtres aboutiront à des pages sans résultats
- or il n’y a rien qui ressemble plus à une page sans résultats … qu’une autre page sans résultats
- et d’autres combinaisons généreront des pages listings identiques ou très très proches
- beaucoup de combinaisons de filtres aboutiront à des pages sans résultats
Bref, quand bien même Google consacrerait plus de crawl budget pour découvrir et indexer vos pages, il y’a de fortes chances qu’il le fasse pas car il estimera vos pages listings comme globalement sans intérêt !
- Côté pages produits, cela peut aussi tourner à la catastrophe, car la présence d’un trop grand nombre de pages facettées peut empêcher les pages produits d’être crawlées et indexées normalement. Quand toutes les urls facettées sont ouvertes, on constate souvent qu’une part importante des fiches produits ne sont plus crawlées ou indexées. Celles qui restent indexées captent moins de trafic.
Bref, laisser Googlebot découvrir les urls des pages filtrées et les laisser toutes crawlables et indexables EST UNE TRES TRES MAUVAISE IDEE;
Comment résoudre le problème ?
L’une des premières choses à faire c’est d’empêcher les urls des pages filtrées d’être découvertes par les bots des moteurs, et que leur syntaxe soit ensuite bloquée pour le crawl et l’indexation.
C’est là que la plupart des propriétaires de site ou leurs développeurs butent sur des écueils qu’ils jugent parfois insurmontables.
Les pages listing filtrées sont souvent générés par des formulaires HTML, gérés en Javascript ou en HTML par une balise <form>. Si le formulaire qui sert à envoyer les paramètres de filtre est en mode POST, tout va bien car l’url de la page filtrée ne changera pas. Mais dès que le site reçoit un minimum de trafic, il y’aura toujours quelqu’un pour faire remarquer qu’on ne peut pas mettre les pages listings produits filtrées en cache avec cette implémentation. Et ce « quelqu’un » aura parfaitement raison.
Sauf que si vous gérez le formulaire en mode GET, vous passerez les paramètres liés aux facettes dans l’url, et si le bot du moteur peut découvrir ces urls, alors elles seront crawlées et indexées et vous retrouvez la catastrophe potentielle décrite plus haut.
Les rel=canonical ne résolvent que 50% du problème
Dans cette situation, l’une des solutions techniques les plus courantes est d’ajouter une balise link rel=’canonical » qui pointe de l’url de la page filtrée vers la page de catégorie non filtré.
Mais ce n’est pas une solution parfaite, loin s’en faut.
Tout d’abord, ce n’est pas une solution fiable à 100% : la balise canonical est un signal que Google utilise pour ne garder que les urls canoniques dans son index. Mais il ne suivra pas toujours vos suggestions ! Surtout si vous envoyez des signaux contradictoires par ailleurs (syntaxe non canonique dans le sitemap XML, syntaxe non canonique dans le maillage interne du site, ou dans les urls des pages des backlinks etc…)
Le résultat, c’est qu’une partie des urls des pages filtrées restera dans l’index.
Mais surtout, vous continuez à obliger Google à crawler 3750000 urls pour trouver les 2500 à indexer ! Ce n’est pas très efficace, et les effets de bord sont probables.
Le noindex est une très mauvaise idée
L’autre solution souvent rencontrée est de placer une balise meta robots avec la valeur d’attribut noindex sur les pages filtrées. C’est encore pire. Certes les pages en trop ne sont plus indexées, mais cette solution n’empêche pas la dilution du pagerank interne. Et cela crée derrière un comportement de crawl imprévisible : une page en noindex ne sera plus crawlée au bout d’un moment, ce qui empêchera la découverte de toutes les pages produits par exemple.
L’utilisation seule d’une meta robots avec la valeur d’attribut noindex est à déconseiller pour cet usage (on verra plus loin que cela peut être utilisé pour faciliter la désindexation des urls de pages filtrées par facette, de manière temporaire).
Notre recommandation : empêcher la découverte, le crawl, et l’indexation des urls de pages filtrées par facettes par défaut
S’agissant des urls des pages filtrées, il faut déjà penser à empêcher leur découverte par les bots des moteurs de recherche.
Car si le bot a découvert une url sur vos page, la bloquer par une directive Disallow dans le robots.txt évitera certes qu’elle soit crawlée, mais pas qu’elle soit indexée. Et du coup, sans traiter cet aspect, on continue d’avoir un souci avec le PR interne (en fait il est maximisé dans le cas de liens trouvés vers des urls bloquées par le robots.txt), et avec le budget de crawl.
Comment éviter la découverte des urls des pages filtrées par facettes ?
Il y’a plusieurs solutions :
- obfusquer les liens : nous ne sommes pas fans de cette solution car elle pose souvent des problèmes de web performance et certaines implémentations n’empêchent pas la découverte de l’url par les moteurs. Pensez à tester votre script avant d’adopter telle ou telle solution d’obfuscation.
- remplacer les liens <a href= »> sur les filtres par des balises <span>. Le filtrage fonctionnera avec l’aide du code javascript sur la page mais le bot ne verra pas les liens. C’est suffisant dans l’immense majorité des cas.
- utiliser une syntaxe « ajax » comme ci-dessous
Une syntaxe normale :
https://www.mondomaine.com/category?id_cat=23&marque=adidas&taille=40
La même avec un #
https://www.mondomaine.com/category#id_cat=23&marque=adidas&taille=40
Lorsque le bot trouvera le lien, il ne retiendra que la section de l'url avant le #
Le lien pointe vers la page non filtrée : https://www.mondomaine.com/category
Un petit script JS convertit l'url dans sa version "technique" compréhensible par le moteur de catalogue et le tour est joué
Comment faire si Google garde de nombreuses pages filtrées dans son index
Sur beaucoup de sites ecommerce, les solutions pour gérer les urls des pages filtrées ne traitent pas le problème de la découverte de ces urls par les bots sur les pages du site. Après avoir réglé le problème en utilisant les solutions évoquées plus haut, ces pages indexées ne vont pas disparaître par enchantement. Cela peut prendre des mois avant que ces urls soient désindexées.
Sauf si vous ajoutez une balise meta robots avec la valeur attribut no index sur les pages concernées. Attention, cela ne marche que si vous n’avez pas encore bloqué le crawl de ces urls via une directive dans le robots.txt! C’est donc une solution temporaire, à mettre en place pendant quelques jours à quelques semaines le temps que le bot puisse découvrir le « noindex » sur ces pages. Ensuite on bloquera le crawl de ces urls.
Bloquer le crawl des urls de pages filtrées
Une fois le problème de la découverte des urls de pages filtrés par facette réglé, il faut bloquer leur crawl à l’aide d’une directive Disallow dans le robots.txt.
Ce n’est pas toujours facile d’écrire des règles simples pour couvrir tous les cas possibles. Surtout depuis que Google a décidé d’abandonner le support des doubles caractères joker dans ses directives. Et rappelons que les caractères joker comme « * » ne sont pas supportés par tous les bots de moteurs.
Pour rendre le blocage simple et efficace dans 100% des cas, il peut être nécessaire de réécrire les syntaxes de pages filtrées.
Par exemple :
Réécrire les urls :
https://www.mondomaine.com/category?id_cat=23&marque=adidas&taille=40
en :
https://www.mondomaine.com/f/category?id_cat=23&marque=adidas&taille=40
L'ajout de /f/ permet d'écrire une directive unique :
Disallow : /f/ qui bloquera toutes les pages filtrées, quelle que soit la chaine de paramètres dérrière (et son ordre et sa complexité)Comment laisser le moteur ne découvrir, crawler et indexer que les urls de pages filtrées constituant de bonnes pages d’atterrissage SEO ?
Ok : maintenant, les urls des pages filtrées par facettes ne sont plus découvrables, et crawlables. Et les urls qui étaient dans l’index ont été désindexées.
Bref notre site ne fait plus 3 750 000 pages, mais à nouveau 2500 ! Ouf.
Mais si laisser Google découvrir, crawler et indexer TOUTES les facettes est décidément est une mauvaise idée, est-ce qu’une page filtrée sera forcément mauvaise pour le SEO ?
Non : dans bien des cas, une page filtrée sur une facette particulière sera une bien meilleure page d’atterrissage que la page listing produit générique.
Par exemple sur la requête « veste en tweed », cette page :
https://www.mondomaine.com/category?id_cat=10&matiere=tweedest une bien meilleure réponse que :
https://www.mondomaine.com/category?id_cat=23 qui liste toutes les vestes.https://www.mondomaine.com/category?id_cat=23 qui liste toutes les vestes.
Comment bloquer TOUTES les urls filtrées par facettes SAUF les quelques exceptions que l’on voudra utiliser comme page d’atterrissage ?
La solution passe par une simple réécriture :
- la première syntaxe servira pour les urls que l’on veut indexer
- la deuxième syntaxe servira pour les urls que l’on ne veut pas voir découvrir, crawler et indexer par les bots
Pour simplifier, ce que l’on fait en général c’est de garder la syntaxe « brute » (non réécrite) pour un des deux types d’urls et on ne réécrit que la suivante
Par exemple :
https://www.mondomaine.com/category?id_cat=10&matiere=tweed
pour les urls filtrées que les bots doivent ignorer (syntaxe brute)
et
https://www.mondomaine.com/lp/category?id_cat=10&matiere=tweed
ou
https://www.mondomaine.com/cat10/f/matiere_tweed
ou
pour les urls que l'on veut que bots découvrent, crawlent et indexentIl suffit de choisir une syntaxe réécrite :
- qui ne sera pas bloquée par la règle qui bloque la syntaxe brute dans le robots.txt
- qui sera rendue « découvrable » en ajoutant les liens pointant vers cette page dans les blocs de navigation (dans les menus, dans les liens suggérés à gauche et à droite
Et le tour est joué.
Navigation à facettes : les recommandations de Google
Notez que Google a une vieille page de recommandations sur la navigation à facettes qui date de 2014.
https://developers.google.com/search/blog/2014/02/faceted-navigation-best-and-5-of-worst
C’est une ressource qui reste intéressante à lire, si on fait abstraction des infos obsolètes (comme l’usage des link rel next/prev pour la pagination.
Salut, merci pour toutes ces infos.
J’ai une petite question concernant la recommandation de « remplacer a hrefs par des span »
Est-ce qu’il s’agit de passer l’attribut href à un span :
1. ancre
ou d’obfusquer, par ex. en base64 ?
2. ancre
Si 1., que sait-on de la crawlabilité de ce type de « lien » ?
Sait-on comment Google considère le contenu de l’attribut href ?
Merci d’avance !
Bonjour,
Le problème de l’obfuscation, c’est que quand cela concerne beaucoup de liens, cela provoque vite des problèmes de performance. Donc c’est mieux de faire plus simple et plus direct.
L’idée c’est d’utiliser un code HTML qui empêchera Google de deviner qu’il y’a un lien.
Dès que Google voit une balise <a href= » »>, il essaie de découvrir le lien qui est derrière. Y compris quand il n’y a pas de href et que la destination est fournie par un bout de JS. Donc obfusquer un lien qui est dans une balise <a>, c’est loin de marcher à tous les coups.
Car si Google voit une balise <a>, il va virtuellement cliquer dessus. C’est un vieux comportement qui date de bien avant Googlebot Evergreen et le Web Rendering Service. Et s’il est téléporté ailleurs que sur le page : il aura découvert le lien (même parfois s’il est obfusqué).
Par contre, si on code en JS un comportement de téléportation vers une autre url à partir d’une action sur la zone définie par une <span>…</span> (ou une <div>, choisissez juste un élément du DOM qui ne sert pas à créer des liens), alors, Googlebot ne découvrira pas le lien. Et cela fonctionne avec ou sans obfuscation.
En clair : si Googlebot voit une balise <a> il va cliquer dessus pour voir où cela mène.
Mais Googlebot ne testera pas une action sur toutes les zones possibles de la page pour voir ce que cela fait. Et donc pas sur toutes les span, p, div etc…
Il y’a des exceptions donc cela vaut le coup de tester le code pour être sûr que la méthode permet bien d’éviter la découverte des urls… Même chose avec l’obfuscation.
D’accord je vous remercie, c’est plus clair ! 🙂
Merci pour ces explications très claires qui serviront probablement à beaucoup de monde.
Cependant, en fonction du CMS utilisé il n’est pas forcément possible de bloquer TOUTES les urls filtrées par facettes SAUF les quelques exceptions que l’on voudra utiliser comme page d’atterrissage. C’est au cas par cas.